Chapter 3 Policy Gradient Methods
In Chapter 2, we relaxed two key assumptions of the MDP introduced in Chapter 1:
- Unknown dynamics: the transition function \(P\) was no longer assumed to be known.
- Continuous states: the state space \(\mathcal{S}\) was extended from finite to continuous.
When only the dynamics are unknown but the MDP remains tabular, we introduced generalized versions of policy iteration (e.g., SARSA) and value iteration (e.g., Q-learning). These algorithms can recover near-optimal value functions with strong convergence guarantees.
When both the dynamics are unknown and the state space is continuous, tabular methods become infeasible. In this setting, we employed function approximation to represent value functions, and generalized SARSA and Q-learning accordingly. We also introduced stabilization techniques such as experience replay and target networks to ensure more reliable learning.
In this chapter, we relax a third assumption: the action space \(\mathcal{A}\) is also continuous. This setting captures many important real-world systems, such as autonomous vehicles and robots. Handling continuous actions requires a departure from the value-based methods of Chapter 2. The key difficulty is that even if we had access to a near-optimal action-value function \(Q(s,a)\), selecting the control action requires solving \[ \max_a Q(s,a), \] which is often computationally expensive and can lead to suboptimal solutions.
To address this challenge, we introduce a new paradigm: policy gradient methods. Rather than learning value functions to derive policies indirectly, we directly optimize parameterized policies using gradient-based methods.
We begin this chapter by reviewing the fundamentals of gradient-based optimization, and then build upon them to develop algorithms for searching optimal policies via policy gradients.
3.1 Gradient-based Optimization
Gradient-based optimization is the workhorse behind most modern machine learning algorithms, including policy gradient methods. The central idea is to iteratively update the parameters of a model in the direction that most improves an objective function.
3.1.1 Basic Setup
Suppose we have a differentiable objective function \(J(\theta)\), where \(\theta \in \mathbb{R}^d\) represents the parameter vector. The goal is to find \[ \theta^\star \in \arg\max_\theta J(\theta). \]
The gradient of the objective with respect to the parameters, \[ \nabla_\theta J(\theta) = \begin{bmatrix} \frac{\partial J}{\partial \theta_1} & \frac{\partial J}{\partial \theta_2} & \cdots & \frac{\partial J}{\partial \theta_d} \end{bmatrix}^\top, \] provides the local direction of steepest ascent. Gradient-based optimization uses this direction to iteratively update the parameters. Note that modern machine learning software tools such as PyTorch allow the user to conveniently query the gradient of any function \(J\) defined by neural networks.
3.1.2 Gradient Ascent and Descent
The simplest method is gradient ascent (for maximization):
\[
\theta_{k+1} = \theta_k + \alpha \nabla_\theta J(\theta_k),
\]
where \(\alpha > 0\) is the learning rate.
For minimization, the update rule uses gradient descent:
\[
\theta_{k+1} = \theta_k - \alpha \nabla_\theta J(\theta_k).
\]
The choice of learning rate \(\alpha\) is critical:
- Too large \(\alpha\) can cause divergence.
- Too small \(\alpha\) leads to slow convergence.
3.1.2.1 Convergence Guarantees
For convex functions \(J(\theta)\), gradient descent (or ascent) can be shown to converge to the global optimum under appropriate conditions on the learning rate.
For non-convex functions—which are common in reinforcement learning—gradient methods may only find so-called first-order stationary points, i.e., points \(\theta\) at which the gradient \(\nabla_\theta J(\theta) = 0\). Nevertheless, they remain effective in practice.
TODO: graph different stationary points
We now formalize the convergence speed of Gradient Descent (GD) for minimizing a smooth convex function. We switch to the minimization convention and write the objective as \(f:\mathbb{R}^d \to \mathbb{R}\) (to avoid sign confusions with \(J\) used for maximization). We assume exact gradients \(\nabla f(\theta)\) are available.
Setup and Assumptions.
(Convexity) For all \(\theta,\vartheta\in\mathbb{R}^d\), \[\begin{equation} f(\vartheta) \;\ge\; f(\theta) + \nabla f(\theta)^\top(\vartheta-\theta). \tag{3.1} \end{equation}\]
(\(L\)-smoothness) The gradient is \(L\)-Lipschitz: for all \(\theta,\vartheta\), \[\begin{equation} \|\nabla f(\vartheta)-\nabla f(\theta)\| \;\le\; L\|\vartheta-\theta\|. \tag{3.2} \end{equation}\] Equivalently (the descent lemma), for all \(\theta,\Delta\), \[\begin{equation} f(\theta+\Delta) \;\le\; f(\theta) + \nabla f(\theta)^\top \Delta + \frac{L}{2}\|\Delta\|^2. \tag{3.3} \end{equation}\]
Consider Gradient Descent with a constant stepsize \(\alpha>0\): \[ \theta_{k+1} \;=\; \theta_k \;-\; \alpha\, \nabla f(\theta_k). \]
Theorem 3.1 (GD on smooth convex function) Let \(f\) be convex and \(L\)-smooth with a minimizer \[ \theta^\star\in\arg\min_\theta f(\theta). \] and the global minimum \(f^\star = f(\theta^\star)\). If \(0<\alpha\le \frac{2}{L}\), then the GD iterates satisfy for all \(k\ge 0\): \[\begin{equation} f(\theta_k) - f^\star \leq \frac{2 (f(\theta_0) - f^\star) \Vert \theta_0 - \theta^\star \Vert^2 }{2 \Vert \theta_0 - \theta^\star \Vert^2 + k\alpha ( 2 - L \alpha) (f(\theta_0) - f^\star)} \tag{3.4} \end{equation}\] In particular, choosing \(\alpha=\frac{1}{L}\) yields the canonical \(O(1/k)\) convergence rate in suboptimality: \[\begin{equation} f(\theta_k) - f^\star \leq \frac{2L \Vert \theta_0 - \theta^\star \Vert^2}{k+4} \tag{3.5} \end{equation}\]
Proof. See Theorem 2.1.14 and Corollary 2.1.2 in (Nesterov 2018).
Strongly Convex Case (Linear Rate). If, in addition, \(f\) is \(\mu\)-strongly convex (\(\mu>0\)), i.e., for all \(\theta,\vartheta\in\mathbb{R}^d\), \[\begin{equation} f(\vartheta)\;\ge\; f(\theta) + \nabla f(\theta)^\top(\vartheta-\theta) \;+\; \frac{\mu}{2}\,\|\vartheta-\theta\|^2. \tag{3.6} \end{equation}\] Then, GD with \(0<\alpha\le \frac{2}{\mu + L}\) enjoys a linear (geometric) rate:
Theorem 3.2 (GD on smooth strongly convex function) If \(f\) is \(L\)-smooth and \(\mu\)-strongly convex, then for \(0<\alpha\le \frac{2}{\mu + L}\), \[\begin{equation} \Vert \theta_k - \theta^\star \Vert^2 \leq \left( 1 - \frac{2\alpha \mu L}{\mu + L} \right)^k \Vert \theta_0 - \theta^\star \Vert^2. \tag{3.7} \end{equation}\] If \(\alpha = \frac{2}{\mu + L}\), then \[\begin{equation} \begin{split} \Vert \theta_k - \theta^\star \Vert & \leq \left( \frac{Q_f - 1}{Q_f + 1} \right)^k \Vert \theta_0 - \theta^\star \Vert \\ f(\theta_k) - f^\star & \leq \frac{L}{2} \left( \frac{Q_f - 1}{Q_f + 1} \right)^{2k} \Vert \theta_0 - \theta^\star \Vert^2, \end{split} \tag{3.8} \end{equation}\] where \(Q_f = L/\mu\).
Proof. See Theorem 2.1.15 in (Nesterov 2018).
Practical Notes.
The step size \(\alpha=\frac{1}{L}\) is optimal among fixed stepsizes for the above worst-case bounds on smooth convex \(f\).
In practice, backtracking line search or adaptive schedules can approach similar behavior without knowing \(L\).
For policy gradients (which maximize \(J\)), apply the results to \(f=-J\) and flip the update sign (gradient ascent). The smooth/convex assumptions rarely hold globally in RL, but these results calibrate expectations about step sizes and motivate variance reduction and curvature-aware methods used later.
3.1.3 Stochastic Gradients
In reinforcement learning and other large-scale machine learning problems, computing the exact gradient \(\nabla_\theta J(\theta)\) is often infeasible. Instead, we use an unbiased estimator \(\hat{\nabla}_\theta J(\theta)\) computed from a subset of data (or trajectories in RL). The update becomes \[ \theta_{k+1} = \theta_k + \alpha \hat{\nabla}_\theta J(\theta_k). \]
This approach, known as stochastic gradient ascent/descent (SGD), trades off exactness for computational efficiency. Variance in the gradient estimates plays an important role in convergence speed and stability.
3.1.3.1 Convergence Guarantees
We now turn to the convergence guarantees of stochastic gradient methods, which replace exact gradients with unbiased noisy estimates. Throughout this section we consider the minimization problem \(\min_\theta f(\theta)\) and assume \(\nabla f\) is available only through a stochastic oracle.
Setup and Assumptions.
Let \(f:\mathbb{R}^d\!\to\!\mathbb{R}\) be differentiable. At iterate \(\theta_k\), we observe a random vector \(g_k\) such that \[ \mathbb{E}[\,g_k \mid \theta_k\,] = \nabla f(\theta_k) \quad\text{and}\quad \mathbb{E}\!\left[\|g_k-\nabla f(\theta_k)\|^2 \mid \theta_k\right] \le \sigma^2. \] We will also use one of the following standard regularity conditions:
- (Convex + \(L\)-smooth) \(f\) is convex and the gradient is \(L\)-Lipschitz.
- (Strongly convex + \(L\)-smooth) \(f\) is \(\mu\)-strongly convex and \(L\)-smooth.
We consider the SGD update \[ \theta_{k+1} \;=\; \theta_k - \alpha_k\, g_k, \] and define the averaged iterate \[ \bar\theta_K := \frac{1}{K+1}\sum_{k=0}^{K}\theta_k. \]
Theorem 3.3 (SGD on smooth convex function) Assume \(f\) is convex and \(L\)-smooth. Suppose there exists \(G\!>\!0\) with \(\mathbb{E}\|g_k\|^2 \le G^2\) for all \(k\).
Choose a constant stepsize \(\alpha_k = \alpha > 0\). Then for all \(K \ge 1\), \[\begin{equation} \mathbb{E}\big[f(\bar\theta_K)\big] - f^\star \leq \frac{\Vert \theta_0 - \theta^\star \Vert^2}{2 \alpha (K+1)} + \frac{\alpha G^2}{2}. \tag{3.9} \end{equation}\]
Choose a diminishing step size \(\alpha_k = \frac{\Vert \theta_0 - \theta^\star \Vert}{G \sqrt{k+1}}\), then \[\begin{equation} \mathbb{E}\big[f(\bar\theta_K)\big] - f^\star \leq \frac{\Vert \theta_0 - \theta^\star \Vert G}{\sqrt{K+1}} = \mathcal{O}\left( \frac{1}{\sqrt{K}} \right). \tag{3.10} \end{equation}\]
Proof. See this lecture note and (Garrigos and Gower 2023).
Remarks.
The bound is on the averaged iterate \(\bar\theta_K\) (the last iterate may be worse by constants without further assumptions).
Replacing the second-moment bound by a variance bound \(\sigma^2\) yields the same rate with \(G^2\) replaced by \(\sigma^2 + \sup_k\|\nabla f(\theta_k)\|^2\).
With a constant stepsize, SGD converges \(\mathcal{O}(1/k)\) up to a neighborhood set by the gradient noise.
The next theorem states the convergence rate of SGD for minimizing strongly convex functions.
Theorem 3.4 (SGD on smooth strongly convex function) Assume \(f\) is \(\mu\)-strongly convex and \(L\)-smooth, and \(\mathbb{E}\!\left[\|g_k\|^2 \right]\le G^2\).
With stepsize \(\alpha_k = \frac{1}{\mu(k+1)}\), the SGD iterates satisfy for all \(K\!\ge\!1\),
\[\begin{equation}
\begin{split}
\mathbb{E}[f(\bar\theta_K)] - f^\star & \leq \frac{G^2}{2 \mu (K+1)} (1 + \log(K+1)), \\
\mathbb{E} \Vert \bar\theta_K - \theta^\star \Vert^2 & \leq \frac{Q}{K+1}, \ \ Q = \max \left( \frac{G^2}{\mu^2}, \Vert \theta_0 - \theta^\star \Vert^2 \right).
\end{split}
\tag{3.11}
\end{equation}\]
Proof. See this lecture note and (Garrigos and Gower 2023).
Practical Takeaways for Policy Gradients.
Use diminishing stepsizes for theoretical convergence (\(\alpha_k \propto 1/\sqrt{k}\) for general convex, \(\alpha_k \propto 1/k\) for strongly convex surrogates).
With constant stepsizes, expect fast initial progress down to a variance-limited plateau; lowering variance (e.g., via baselines/advantage estimation) is as important as tuning \(\alpha\).
TODO: graph the different trajectories between minimizing a convex function using GD and SGD.
3.1.4 Beyond Vanilla Gradient Methods
Several refinements to basic gradient updates are widely used:
- Momentum methods: incorporate past gradients to smooth updates and accelerate convergence.
- Adaptive learning rates (Adam, RMSProp, AdaGrad): adjust the learning rate per parameter based on historical gradient magnitudes.
- Second-order methods: approximate or use curvature information (the Hessian) for more informed updates, though often impractical in high dimensions.
3.2 Policy Gradients
Policy gradients optimize a parameterized stochastic policy directly, without requiring an explicit action-value maximization step. They are applicable to both finite and continuous action spaces and are especially useful when actions are continuous or when “\(\arg\max\)” over \(Q(s,a)\) is costly or ill-posed.
3.2.1 Setup
We consider a Markov decision process (MDP) with (possibly continuous) state space \(\mathcal{S}\), action space \(\mathcal{A}\), unknown dynamics \(P\), reward function \(R(s,a)\), and discount factor \(\gamma\in[0,1)\). Let \(\pi_\theta(a\mid s)\) be a differentiable stochastic policy with parameters \(\theta\in\mathbb{R}^d\).
Trajectory. A state-action trajectory is \(\tau=(s_0,a_0,s_1,a_1,\dots,s_{T})\) with probability density/mass \[\begin{equation} p_\theta(\tau) = \rho(s_0)\prod_{t=0}^{T-1} \pi_\theta(a_t\mid s_t)\,P(s_{t+1}\mid s_t,a_t), \tag{3.12} \end{equation}\] where \(\rho\) is the initial state distribution and \(T\) is the (random or fixed) episode length.
Return. Define the (discounted) return \[\begin{equation} R(\tau) \;=\; \sum_{t=0}^{T-1}\gamma^t R(s_t,a_t), \tag{3.13} \end{equation}\] and the return-to-go \[\begin{equation} g_t \;=\; \sum_{t'=t}^{T-1}\gamma^{t'-t} R(s_{t'},a_{t'}). \tag{3.14} \end{equation}\]
Optimization objective. The goal is to maximize the expected return \[\begin{equation} J(\theta) \;\equiv\; \mathbb{E}_{\tau\sim p_\theta}\!\left[R(\tau)\right] \;=\; \mathbb{E}\!\left[\sum_{t=0}^{T-1}\gamma^t R(s_t,a_t)\right], \tag{3.15} \end{equation}\] where the expectation is taken over the randomness in (i) the initial state \(s_0 \sim \rho\), (ii) the policy \(\pi_\theta\), and (iii) the transition dynamics \(P\).
3.2.1.1 Policy models
Finite action spaces (\(\mathcal{A}\) discrete). A common choice is a softmax (categorical) policy over a score (logit) function \(f_\theta(s,a)\): \[\begin{equation} \pi_\theta(a\mid s) \;=\; \frac{\exp\{f_\theta(s,a)\}}{\sum_{a'\in\mathcal{A}}\exp\{f_\theta(s,a')\}}. \tag{3.16} \end{equation}\] Here we use \(\exp\{f_\theta(s,a)\} = e^{f_\theta(s,a)}\) for pretty formatting. Typically \(f_\theta\) is a neural network or a linear function over features.
Continuous action spaces (\(\mathcal{A}\subseteq\mathbb{R}^m\)). A standard choice is a Gaussian policy: \[\begin{equation} \pi_\theta(a\mid s) \;=\; \mathcal{N}\!\big(a;\;\mu_\theta(s),\,\Sigma_\theta(s)\big), \tag{3.17} \end{equation}\] where \(\mu_\theta(s)\) and (often diagonal) covariance \(\Sigma_\theta(s)\) are differentiable functions (e.g., neural networks) parameterized by \(\theta\). The policy \(\pi_\theta(a \mid s)\) samples actions from the Gaussian parameterized by \(\mu_\theta(s)\) and \(\Sigma_\theta(s)\). Other choices include squashed Gaussians (e.g., \(\tanh\)) or Beta distributions for bounded actions.
3.2.2 The Policy Gradient Lemma
With the gradient-based optimization machinery from Section 3.1, a natural strategy for the policy optimization problem in (3.15) is gradient ascent on the objective \(J(\theta)\). Consequently, the central task is to characterize the ascent direction, i.e., to compute \(\nabla_\theta J(\theta)\).
The policy gradient lemma, stated below, provides exactly this characterization. Crucially, it expresses \(\nabla_\theta J(\theta)\) in terms of the policy’s score function \(\nabla_\theta \log \pi_\theta(a\mid s)\) and returns, without differentiating through the environment dynamics. This likelihood-ratio form makes policy optimization feasible even when the transition model is unknown or non-differentiable.
Theorem 3.5 (Policy Gradient Lemma) Let \(J(\theta)=\mathbb{E}_{\tau \sim p_\theta}[R(\tau)]\) as defined in (3.15) Then: \[\begin{equation} \nabla_\theta J(\theta) \;=\; \mathbb{E}_{\tau\sim p_\theta} \Big[R(\tau)\,\nabla_\theta \log p_\theta(\tau)\Big] \;=\; \mathbb{E}_{\tau\sim p_\theta} \Bigg[\sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t\mid s_t)\;R(\tau)\Bigg]. \tag{3.18} \end{equation}\] By causality (future action does not affect past reward), the full return can be replaced by return-to-go: \[\begin{equation} \nabla_\theta J(\theta) \;=\; \mathbb{E}_{\tau\sim p_\theta} \Bigg[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\;g_t\Bigg]. \tag{3.19} \end{equation}\] Equivalently, using value functions, \[\begin{equation} \nabla_\theta J(\theta) \;=\; \frac{1}{1-\gamma} \mathbb{E}_{s\sim d_\theta,\;a\sim\pi_\theta} \Big[\nabla_\theta \log \pi_\theta(a\mid s)\,Q^{\pi_\theta}(s,a)\Big], \tag{3.20} \end{equation}\] where \(d_\theta\) is the (discounted) on-policy state visitation distribution for infinite-horizon MDPs: \[\begin{equation} d_\theta(s) = (1 - \gamma) \sum_{t=0}^{\infty} \gamma^t \Pr_\theta(s_t=s). \tag{3.21} \end{equation}\]
Proof. We prove the three equivalent forms step by step. Throughout, we assume \(\theta\) parameterizes only the policy \(\pi_\theta\) (not the dynamics \(P\) nor the initial distribution \(\rho\)), and that interchanging \(\nabla_\theta\) with the trajectory integral/sum is justified (e.g., bounded rewards and finite horizon or standard dominated-convergence conditions). Let the return-to-go \(g_t\) be defined as in (3.14).
Step 1 (Log-derivative trick). Write the objective as an expectation over trajectories: \[ J(\theta) \;=\; \int R(\tau)\, p_\theta(\tau)\, d\tau. \] Differentiate under the integral and use \[\begin{equation} \nabla_\theta p_\theta(\tau)=p_\theta(\tau)\nabla_\theta\log p_\theta(\tau) \tag{3.22} \end{equation}\] we can write: \[ \nabla_\theta J(\theta) = \int R(\tau)\,\nabla_\theta p_\theta(\tau)\, d\tau = \int R(\tau)\, p_\theta(\tau)\,\nabla_\theta \log p_\theta(\tau)\, d\tau = \mathbb{E}_{\tau\sim p_\theta}\!\big[R(\tau)\,\nabla_\theta \log p_\theta(\tau)\big], \] which is (3.18) up to expanding \(\log p_\theta(\tau)\). To see why (3.22) is true, write \[ \nabla_\theta \log p_\theta(\tau) = \frac{1}{p_\theta(\tau)} \nabla_\theta p_\theta(\tau), \] using the chain rule.
Step 2 (Policy-only dependence). Factor the trajectory likelihood/mass: \[ p_\theta(\tau) = \rho(s_0)\,\prod_{t=0}^{T-1}\pi_\theta(a_t\mid s_t)\,P(s_{t+1}\mid s_t,a_t). \] Since \(\rho\) and \(P\) do not depend on \(\theta\), \[ \log p_\theta(\tau) = \text{const} \;+\; \sum_{t=0}^{T-1}\log \pi_\theta(a_t\mid s_t) \quad\Rightarrow\quad \nabla_\theta \log p_\theta(\tau) \;=\; \sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t\mid s_t). \] Substitute into Step 1 to obtain the second equality in (3.18): \[ \nabla_\theta J(\theta) = \mathbb{E}_{\tau\sim p_\theta}\!\Bigg[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,R(\tau)\Bigg]. \]
Step 3 (Causality \(\Rightarrow\) return-to-go). Expand \(R(\tau)=\sum_{t=0}^{T-1}\gamma^{t} r_{t}\) (with \(r_{t}:=R(s_{t},a_{t})\)) and swap sums: \[ \mathbb{E} \Bigg[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,R(\tau)\Bigg] = \sum_{t=0}^{T-1}\sum_{t'=0}^{T-1}\mathbb{E} \big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\gamma^{t'} r_{t'}\big]. \] For \(t'<t\), the factor \(\gamma^{t'} r_{t'}\) is measurable w.r.t. the history \(\mathcal{F}_t=\sigma(s_0,a_0,\dots,s_t)\), while \[ \mathbb{E} \big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big|\,\mathcal{F}_t\big] = \sum_{a} \pi_\theta(a\mid s_t)\,\nabla_\theta \log \pi_\theta(a\mid s_t) = \nabla_\theta \sum_{a}\pi_\theta(a\mid s_t) = \nabla_\theta 1 = 0, \] (and analogously with integrals for continuous \(\mathcal{A}\)). Hence by the tower property, \[ \mathbb{E} \big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\gamma^{t'} r_{t'}\big]=0\quad\text{for all }t'<t. \] Therefore only the terms with \(t'\ge t\) survive, and \[ \nabla_\theta J(\theta) = \sum_{t=0}^{T-1}\mathbb{E} \Big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\sum_{t'=t}^{T-1}\gamma^{t'} r_{t'}\Big] = \mathbb{E} \Bigg[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,g_t\Bigg], \] which is (3.19).
Step 4 (Value-function form). Condition on \((s_t,a_t)\) and use the definition of the action-value function: \[ Q^{\pi_\theta}(s_t,a_t) \;\equiv\; \mathbb{E}\!\left[g_t \,\middle|\, s_t,a_t\right]. \] Taking expectations then yields \[ \mathbb{E} \big[\gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,g_t\big] = \mathbb{E} \big[\gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,Q^{\pi_\theta}(s_t,a_t)\big]. \] Summing over \(t\) and collecting terms with the (discounted) on-policy state visitation distribution \(d_\theta\) (for the infinite-horizon case, e.g., \(d_\theta(s)=(1-\gamma)\sum_{t=0}^\infty \gamma^t\,\Pr_\theta(s_t=s)\); for finite \(T\), use the corresponding finite-horizon weighting), we obtain \[ \nabla_\theta J(\theta) \;=\; \mathbb{E}_{s\sim d_\theta,\;a\sim \pi_\theta} \Big[\nabla_\theta \log \pi_\theta(a\mid s)\,Q^{\pi_\theta}(s,a)\Big], \] which is (3.20).
Conclusion. Combining Steps 1–4 proves all three stated forms of the policy gradient.
3.2.3 REINFORCE
The policy gradient lemma immediately gives us an algorithm. Specifically, the gradient receipe in (3.18) tells us that if we generate one trajectory \(\tau\) by following the policy \(\pi\), then \[\begin{equation} \widehat{\nabla_\theta J} = \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t \mid s_t) R(\tau) \tag{3.23} \end{equation}\] is an unbiased estimator of the true gradient.
With this sample gradient estimator, we obtain the classical REINFORCE algorithm.
Single-Trajectory (Naive) REINFORCE
- Initialize \(\theta_0\) for the initial policy \(\pi_{\theta_0}(a \mid s)\)
- For \(k=0,1,\dots,\) do:
- Obtain a trajectory \(\tau \sim p_{\theta_k}\)
- Compute the stochastic gradient \(g_k\) as in (3.23)
- Update \(\theta_{k+1} = \theta_k + \alpha_k g_k\)
To reduce variance of the gradient estimator, we can use a minibatch of trajectories. For example, given a batch of \(N\) trajectories \(\{\tau^{(i)}\}_{i=1}^N\) collected by \(\pi_\theta\), define for each timestep the return-to-go \[ g_t^{(i)} = \sum_{t'=t}^{T^{(i)}-1} \gamma^{t'-t} R\!\left(s_{t'}^{(i)},a_{t'}^{(i)}\right). \] An unbiased gradient estimator, from (3.19) is \[\begin{equation} \widehat{\nabla_\theta J} \;=\; \frac{1}{N}\sum_{i=1}^N \sum_{t=0}^{T^{(i)}-1} \gamma^t \nabla_\theta \log \pi_\theta \big(a_t^{(i)}\mid s_t^{(i)}\big) g_t^{(i)}. \tag{3.24} \end{equation}\]
This leads to the following minibatch REINFORCE algorithm.
Minibatch REINFORCE
- Initialize \(\theta_0\) for the initial policy \(\pi_{\theta_0}(a \mid s)\)
- For \(k=0,1,\dots,\) do:
- Obtain N trajectories \(\{ \tau^{(i)} \}_{i=1}^N \sim p_{\theta_k}\)
- Compute the stochastic gradient \(g_k\) as in (3.24)
- Update \(\theta_{k+1} = \theta_k + \alpha_k g_k\)
We apply both the single-trajectory (naive) REINFORCE and a minibatch variant to the CartPole-v1 balancing task. The results show that variance reduction via minibatching is crucial for stable learning and for obtaining strong policies with policy-gradient methods.
Example 3.1 (REINFORCE for Cart-Pole Balancing) Consider the cart-pole balancing task illustrated in Fig. 3.1. A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The pendulum is placed upright on the cart and the goal is to balance the pole by applying forces in the left and right direction on the cart.
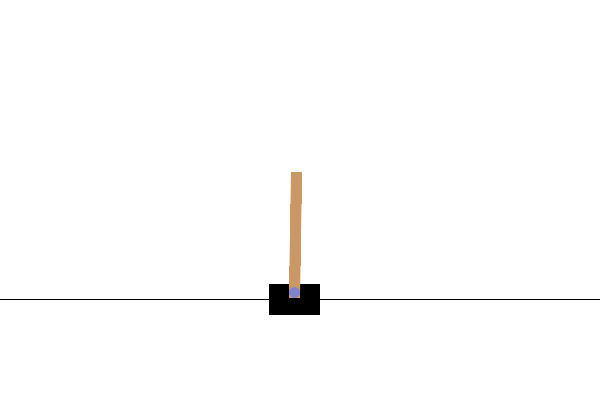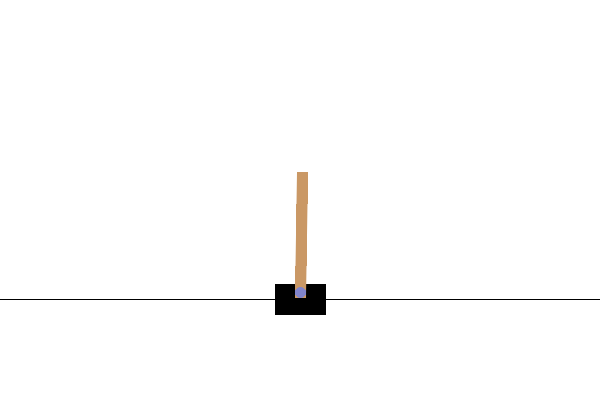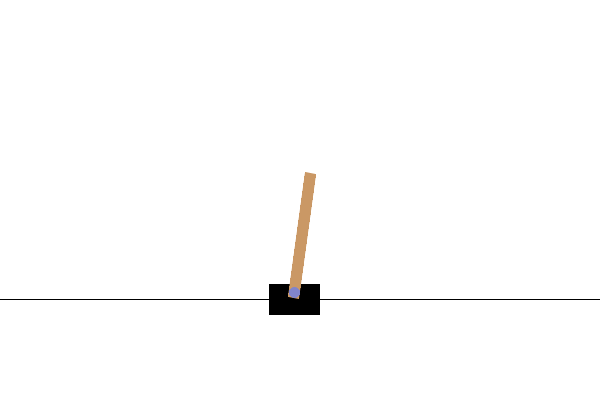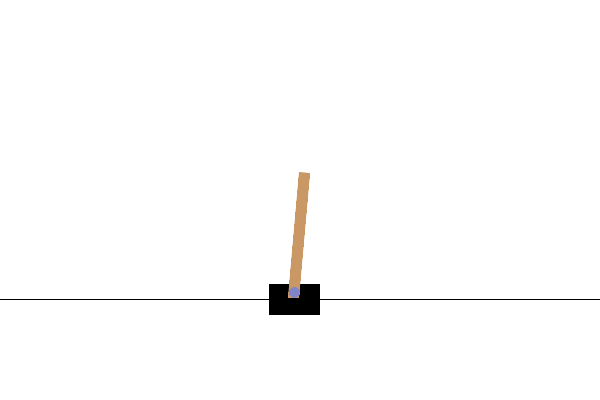
Figure 3.1: Cart Pole balance.
State Space. The state of the cart-pole system is denoted by \(s \in \mathcal{S} \subset \mathbb{R}^4\), containing the position and velocity of the cart, as well as the angle and angular velocity of the pole.
Action Space. The action space \(\mathcal{A}\) is discrete and contains two elements: pushing to the left and pushing to the right.
The dynamics of the MDP is provided by the Gym simulator and is described in the original paper (Barto, Sutton, and Anderson 2012). At the beginning of the episode, all state variables are randomly initialized in \([-0.05,0.05]\) and the goal for the agent is to apply the actions to balance the cart-pole for as long as possible—the agent gets a reward of \(+1\) every step if (1) the pole angle remains between \(-12^\circ\) and \(+12^\circ\) and (2) the cart position remains between \(-2.4\) and \(2.4\). The maximum episode length is \(500\).
We design a policy network in the form of (3.16) since the action space is finite.
REINFORCE. We first apply the naive REINFORCE algorithm where the gradient estimator is computed from a single trajectory as in (3.23). Fig. 3.2 shows the learning curve, which indicates that the REINFORCE algorithm was not able to learn a good policy after 2000 episodes.
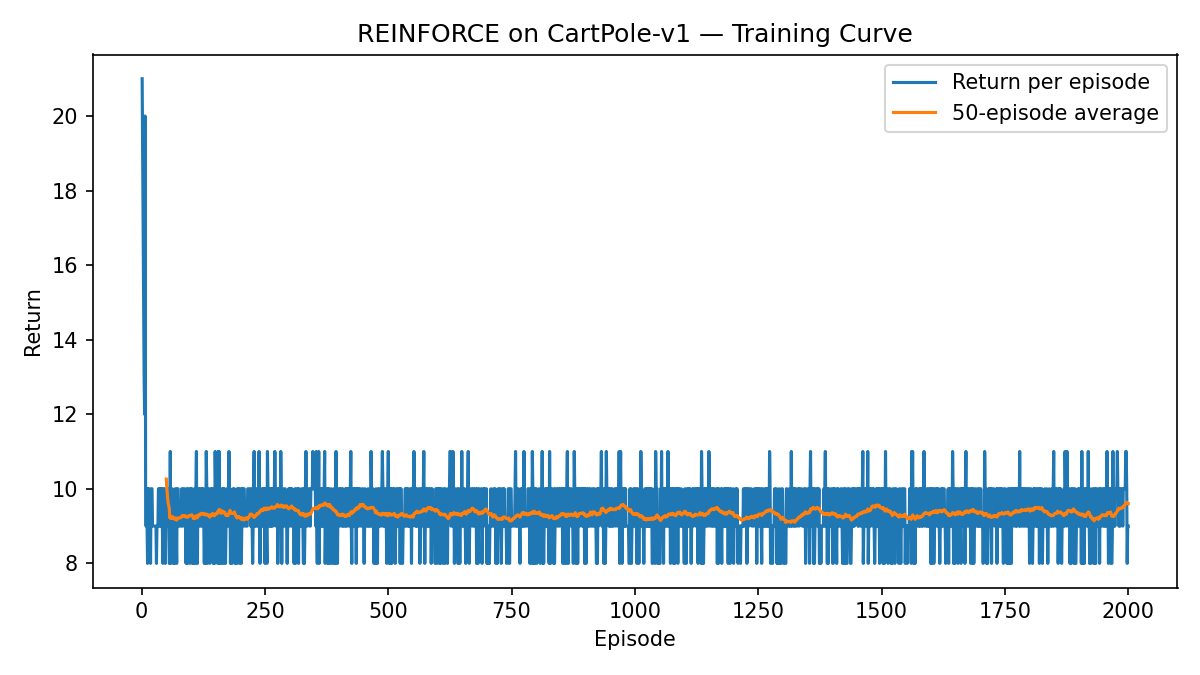
Figure 3.2: Learning curve (Naive REINFORCE).
Minibatch REINFORCE. We then apply the minibatch REINFORCE algorithm where the gradient estimator is computed from multiple (\(20\) in our case) trajectories as in (3.24). Fig. 3.3 shows the learning curve, which shows steady increase in the per-episode return that eventually gets close to the maximum per-episode return \(500\).
Fig. 3.4 shows a rollout video of applying the policy training from minibatch REINFORCE. We can see the policy nicely balances the cart-pole system.
You can play with the code here.

Figure 3.3: Learning curve (Minibatch REINFORCE).

Figure 3.4: Policy rollout (Minibatch REINFORCE).
3.2.4 Baselines and Variance Reduction
From the REINFORCE experiments above, we have seen firsthand that variance reduction is critical for stable policy-gradient learning.
A natural question is: what framework can we use to systematically reduce the variance of the gradient estimator while preserving unbiasedness?
3.2.4.1 Baseline
A key device is a baseline \(b:\mathcal{S}\to\mathbb{R}\) added at each timestep: \[\begin{equation} \widehat{g} \;=\; \sum_{t=0}^{T-1} \gamma^t\,\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t - b(s_t)\big). \tag{3.25} \end{equation}\]
The only difference between (3.25) and the original gradient estimator (3.19) is that the baseline \(b(s_t)\) is subtracted from the return-to-go \(g_t\). The next theorem states that any state-only baseline does not change the expectation of the gradient estimator.
Theorem 3.6 (Baseline Invariance) Let \(b:\mathcal{S}\to\mathbb{R}\) be any function independent of the action \(a_t\). Then \[ \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,b(s_t)\right]=0, \] and thus \[\begin{equation} \nabla_\theta J(\theta) \;=\; \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t - b(s_t)\big)\right]. \tag{3.26} \end{equation}\]
Equivalently, using action-values, \[\begin{equation} \nabla_\theta J(\theta) = \frac{1}{1-\gamma}\, \mathbb{E}_{s\sim d_\theta,\;a\sim\pi_\theta} \!\Big[\nabla_\theta \log \pi_\theta(a\mid s)\,\big(Q^{\pi_\theta}(s,a)-b(s)\big)\Big]. \tag{3.27} \end{equation}\]
Proof. We prove (i) the baseline term has zero expectation, (ii) the baseline-subtracted estimator in (3.26) is unbiased, and (iii) the equivalent \(Q\)-value form (3.27).
Throughout we assume standard conditions ensuring interchange of expectation and differentiation (e.g., bounded rewards with finite horizon or discounted infinite horizon, and a differentiable policy).
Step 1 (Score-function expectation is zero). Fix a state \(s\in\mathcal{S}\). The score function integrates/sums to zero under the policy: \[\begin{equation} \begin{split} \mathbb{E}_{a\sim \pi_\theta(\cdot\mid s)}\!\big[\nabla_\theta \log \pi_\theta(a\mid s)\big] & = \sum_{a\in\mathcal{A}} \pi_\theta(a\mid s)\,\nabla_\theta \log \pi_\theta(a\mid s) = \sum_{a\in\mathcal{A}} \nabla_\theta \pi_\theta(a\mid s) \\ & = \nabla_\theta \sum_{a\in\mathcal{A}} \pi_\theta(a\mid s) = \nabla_\theta 1 = 0, \end{split} \end{equation}\] with the obvious replacement of sums by integrals for continuous \(\mathcal{A}\). This identity is the standard “score has zero mean” property.
Step 2 (Baseline term has zero expectation). Let \(\mathcal{F}_t := \sigma(s_0,a_0,\ldots,s_t)\) be the history up to time \(t\) and recall that \(b(s_t)\) is independent of \(a_t\). Using iterated expectations: \[ \mathbb{E}\!\left[\gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,b(s_t)\right] = \mathbb{E}\!\left[ \gamma^t\, b(s_t)\, \underbrace{\mathbb{E}\!\left[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\middle|\, s_t\right]}_{=\,0~\text{by Step 1}} \right] = 0. \] Summing over \(t\) yields \[ \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,b(s_t)\right]=0. \]
Step 3 (Unbiasedness of the baseline-subtracted estimator). By the policy gradient lemma (likelihood-ratio form with return-to-go; see (3.19)), \[ \nabla_\theta J(\theta) = \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,g_t\right]. \] Subtract and add the baseline term inside the expectation: \[ \begin{split} \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,g_t\right] & = \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t-b(s_t)\big)\right] \;+\; \\ & \quad \quad \underbrace{\mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,b(s_t)\right]}_{=\,0~\text{by Step 2}}. \end{split} \] Therefore (3.26) holds, proving that any state-only baseline preserves unbiasedness.
Step 4 (Equivalent \(Q\)-value form). Condition on \((s_t,a_t)\) and use the definition \(Q^{\pi_\theta}(s_t,a_t):=\mathbb{E}[g_t\mid s_t,a_t]\): \[ \mathbb{E}\!\big[\gamma^t \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t-b(s_t)\big)\big] = \mathbb{E}\!\Big[ \gamma^t\, \mathbb{E}\!\big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t-b(s_t)\big)\mid s_t\big] \Big]. \] Inside the inner expectation (over \(a_t\sim \pi_\theta(\cdot\mid s_t)\)) and using \(b(s_t)\)’s independence from \(a_t\), \[ \mathbb{E}\!\big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\big(g_t-b(s_t)\big)\mid s_t\big] = \mathbb{E}_{a\sim \pi_\theta(\cdot\mid s_t)}\!\Big[\nabla_\theta \log \pi_\theta(a\mid s_t)\,\big(Q^{\pi_\theta}(s_t,a)-b(s_t)\big)\Big]. \] Summing over \(t\) with discount \(\gamma^t\) and collecting terms with the (discounted) on-policy state-visitation distribution \(d_\theta\) (cf. (3.21)) yields the infinite-horizon identity \[ \nabla_\theta J(\theta) = \frac{1}{1-\gamma}\, \mathbb{E}_{s\sim d_\theta,\;a\sim \pi_\theta}\! \Big[\nabla_\theta \log \pi_\theta(a\mid s)\,\big(Q^{\pi_\theta}(s,a)-b(s)\big)\Big], \] which is (3.27).
3.2.4.2 Optimal Baseline and Advantage
Among all state-only baselines \(b(s)\), which one minimizes the variance of the gradient estimator?
Theorem 3.7 (Variance-Minimizing Baseline (per-state)) For the estimator \[ g(s,a)=\nabla_\theta \log \pi_\theta(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big), \] the \(b(s)\) minimizing \(\operatorname{Var}[g\mid s]\) is \[ b^\star(s)= \frac{\mathbb{E}_{a\sim \pi_\theta}\!\left[\| \nabla_\theta \log \pi_\theta(a\mid s)\|^2\, Q^\pi(s,a)\right]} {\mathbb{E}_{a\sim \pi_\theta}\!\left[\| \nabla_\theta \log \pi_\theta(a\mid s)\|^2\right]}. \tag{3.28} \] Assuming that the norm factor \(\Vert \nabla_\theta \log \pi_\theta(a\mid s) \Vert^2\) varies slowly with \(a\), then \[ b^\star(s) \approx V^\pi(s). \]
Proof. Let \(s\in\mathcal{S}\) be fixed and write \[ u(a\mid s) \;\equiv\; \nabla_\theta \log \pi_\theta(a\mid s)\in\mathbb{R}^d, \qquad w(a\mid s) \;\equiv\; \|u(a\mid s)\|^2 \;\ge 0. \] Consider the vector-valued random variable \[ g(s,a) \;=\; u(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big), \] where the randomness is over \(a\sim \pi_\theta(\cdot\mid s)\).
We aim to choose \(b(s)\in\mathbb{R}\) to minimize the conditional variance \[ \operatorname{Var}[g\mid s] \;=\; \mathbb{E}\!\left[\|g(s,a)-\mathbb{E}[g\mid s]\|^2 \,\middle|\, s\right]. \] Using the identity \(\operatorname{Var}[X]=\mathbb{E}\|X\|^2-\|\mathbb{E}X\|^2\) (for vector \(X\) with Euclidean norm), we have \[ \operatorname{Var}[g\mid s] \;=\; \underbrace{\mathbb{E}\!\left[\|g(s,a)\|^2 \mid s\right]}_{\text{depends on } b(s)} \;-\; \underbrace{\big\|\mathbb{E}[g\mid s]\big\|^2}_{\text{independent of } b(s)}. \] We first show that the mean term is independent of \(b(s)\). Indeed, \[ \mathbb{E}[g\mid s] = \mathbb{E}_{a\sim\pi_\theta(\cdot\mid s)}\!\big[u(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big)\big] = \mathbb{E}\!\big[u(a\mid s)\,Q^\pi(s,a)\big] \;-\; b(s)\,\underbrace{\mathbb{E}\!\big[u(a\mid s)\big]}_{=\,0}, \] where \(\mathbb{E}[u(a\mid s)]=\sum_a \pi_\theta(a\mid s)\nabla_\theta\log\pi_\theta(a\mid s)=\nabla_\theta \sum_a \pi_\theta(a\mid s)=\nabla_\theta 1=0\) (replace sums by integrals in the continuous case). Therefore \(\mathbb{E}[g\mid s]\) does not depend on \(b(s)\).
Consequently, minimizing \(\operatorname{Var}[g\mid s]\) is equivalent to minimizing the conditional second moment \[ \mathbb{E}\!\left[\|g(s,a)\|^2 \mid s\right] = \mathbb{E}\!\left[\|u(a\mid s)\|^2 \,\big(Q^\pi(s,a)-b(s)\big)^2 \,\middle|\, s\right] = \mathbb{E}\!\left[w(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big)^2 \,\middle|\, s\right]. \] The right-hand side is a convex quadratic in the scalar \(b(s)\). Differentiate w.r.t. \(b(s)\) and set to zero: \[ \frac{\partial}{\partial b(s)} \mathbb{E}\!\left[w(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big)^2 \,\middle|\, s\right] = -2\,\mathbb{E}\!\left[w(a\mid s)\,\big(Q^\pi(s,a)-b(s)\big)\,\middle|\, s\right] = 0. \] Hence, \[ \mathbb{E}\!\left[w(a\mid s)\,Q^\pi(s,a)\,\middle|\, s\right] = b(s)\,\mathbb{E}\!\left[w(a\mid s)\,\middle|\, s\right], \] and provided \(\mathbb{E}[w(a\mid s)\mid s]>0\) (i.e., the Fisher information at \(s\) is non-degenerate), the unique minimizer is \[ b^\star(s) = \frac{\mathbb{E}_{a\sim\pi_\theta(\cdot\mid s)}\!\left[\| \nabla_\theta \log \pi_\theta(a\mid s)\|^2\, Q^\pi(s,a)\right]} {\mathbb{E}_{a\sim\pi_\theta(\cdot\mid s)}\!\left[\| \nabla_\theta \log \pi_\theta(a\mid s)\|^2\right]}, \] which is (3.28). If \(\mathbb{E}[w(a\mid s)\mid s]=0\) (e.g., a locally deterministic policy), then \(g\equiv 0\) almost surely and any \(b(s)\) attains the minimum.
Finally, when the weight \(w(a\mid s)=\|\nabla_\theta \log \pi_\theta(a\mid s)\|^2\) varies slowly with \(a\) (or is approximately constant) for a fixed \(s\), the ratio simplifies to \[ b^\star(s)\;\approx\;\frac{\mathbb{E}[c(s)\,Q^\pi(s,a)\mid s]}{\mathbb{E}[c(s)\mid s]} \;=\; \mathbb{E}_{a\sim \pi_\theta(\cdot\mid s)}\!\big[Q^\pi(s,a)\big] \;=\; V^\pi(s), \] so that the baseline-subtracted target becomes the advantage \(A^\pi(s,a)=Q^\pi(s,a)-V^\pi(s)\).
When using \(V^\pi(s)\) as the baseline, the baseline-subtracted target is called the advantage function \[\begin{equation} A^{\pi_\theta}(s,a)\;=\;Q^{\pi_\theta}(s,a)-V^{\pi_\theta}(s). \tag{3.29} \end{equation}\] The corresponding minibatch gradient estimator becomes \[\begin{equation} \widehat{\nabla_\theta J} \;=\; \frac{1}{N}\sum_{i=1}^N \sum_{t=0}^{T^{(i)}-1} \gamma^t\, \nabla_\theta \log \pi_\theta \big(a_t^{(i)}\mid s_t^{(i)}\big)\, \widehat{A}_t^{(i)}, \quad \widehat{A}_t^{(i)} \approx g_t^{(i)} - V_\phi \big(s_t^{(i)}\big), \tag{3.30} \end{equation}\] where \(V_\phi\) is a learned approximation to \(V^{\pi_\theta}\).
3.2.4.3 Intuition for the Advantage
The advantage
\[
A^\pi(s,a) \;=\; Q^\pi(s,a) - V^\pi(s)
\]
measures how much better or worse action \(a\) is at state \(s\) relative to the policy’s average action quality \(V^\pi(s)=\mathbb{E}_{a\sim\pi}[Q^\pi(s,a)\mid s]\).
Hence \(\mathbb{E}_{a\sim\pi}[A^\pi(s,a)\mid s]=0\): it is a relative score.
With a value baseline, the policy-gradient update is \[ \nabla_\theta J(\theta) \;=\; \frac{1}{1-\gamma}\, \mathbb{E}_{s\sim d_\pi,\;a\sim\pi}\!\big[ \nabla_\theta \log \pi_\theta(a\mid s)\,A^\pi(s,a) \big]. \]
If \(A^\pi(s,a) > 0\): the term \(\nabla_\theta \log \pi_\theta(a\mid s)\,A^\pi(s,a)\) increases \(\log \pi_\theta(a\mid s)\) (and thus \(\pi_\theta(a\mid s)\))—the policy puts more probability mass on actions that outperformed its average at \(s\).
If \(A^\pi(s,a) < 0\): it decreases \(\log \pi_\theta(a\mid s)\)—the policy puts less probability mass on actions that underperformed at \(s\).
If \(A^\pi(s,a) \approx 0\): the action performed about as expected; the update at that \((s,a)\) is negligible.
Subtracting \(V^\pi(s)\) centers returns per state, so the update depends only on relative goodness. This:
preserves unbiasedness (baseline invariance),
reduces variance (no large, shared offset),
focuses learning on which actions at \(s\) should get more/less probability.
3.2.4.4 REINFORCE with a Learned Value Baseline
Recall that in Section 2.2, we have introduced multiple algorithms that can learn an approximate value function for policy evaluation. For example, we can use Monte Carlo estimation.
We now combine REINFORCE with a learned baseline \(V_\phi(s)\approx V^{\pi_\theta}(s)\), yielding a lower-variance update while keeping the estimator unbiased.
Minibatch REINFORCE with a Learned Value Baseline
Inputs: policy \(\pi_\theta(a\mid s)\), value \(V_\phi(s)\), discount \(\gamma\in[0,1)\), stepsizes \(\alpha_\theta,\alpha_\phi>0\), batch size \(N\).
Convergence controls: tolerance \(\varepsilon>0\), maximum inner steps \(K_{\max}\) (value-fit loop), optional patience \(P\).
Collect trajectories. Roll out \(N\) on-policy trajectories \(\{\tau^{(i)}\}_{i=1}^N\) using \(\pi_\theta\).
For each trajectory \(i\) and timestep \(t\), record \((s_t^{(i)},a_t^{(i)},r_t^{(i)})\).Compute returns-to-go. For each \(i,t\), \[ g_t^{(i)} \;=\; \sum_{t'=t}^{T^{(i)}-1} \gamma^{\,t'-t}\, r_{t'}^{(i)}. \]
Fit the value to convergence (critic inner loop). Define the batch regression loss \[ \mathcal{L}_V(\phi) \;=\; \frac{1}{N}\sum_{i=1}^N \sum_{t=0}^{T^{(i)}-1} \big(g_t^{(i)} - V_\phi(s_t^{(i)})\big)^2. \] Perform gradient steps on \(\phi\) until convergence on this fixed batch: \[ \phi \leftarrow \phi - \alpha_\phi \,\nabla_\phi \mathcal{L}_V(\phi). \] Repeat for \(k=1,\dots,K_{\max}\) or until \[ \frac{\mathcal{L}_V^{(k-1)}-\mathcal{L}_V^{(k)}}{\max\{1,|\mathcal{L}_V^{(k-1)}|\}} < \varepsilon \] for \(M\) consecutive checks. Denote the (approximately) converged parameters by \(\phi^\star\).
Form (optionally standardized) advantages using the converged value. \[ \widehat{A}_t^{(i)} \;=\; g_t^{(i)} - V_{\phi^\star}\!\big(s_t^{(i)}\big), \qquad \tilde{A}_t^{(i)} \;=\; \frac{\widehat{A}_t^{(i)} - \mu_A}{\sigma_A+\delta}\ \ (\text{optional, batch-wise}), \] where \(\mu_A,\sigma_A\) are the mean and std of \(\{\widehat{A}_t^{(i)}\}\) over the whole batch, and \(\delta>0\) is a small constant.
Single policy (actor) update. Using the converged baseline, take one ascent step: \[ \theta \;\leftarrow\; \theta \;+\; \alpha_\theta \cdot \frac{1}{N}\sum_{i=1}^N \sum_{t=0}^{T^{(i)}-1} \gamma^t\,\nabla_\theta \log \pi_\theta \big(a_t^{(i)}\mid s_t^{(i)}\big)\,\tilde{A}_t^{(i)}. \] (If not standardizing, use \(\widehat{A}_t^{(i)}\) in place of \(\tilde{A}_t^{(i)}\).)
Repeat from Step 1 with the updated policy.
Notes.
By baseline invariance, subtracting \(V_{\phi^\star}(s)\) keeps the policy-gradient unbiased while reducing variance.
Converging the critic on each fixed batch (Steps 3–4) approximates the variance-minimizing baseline for that batch before a single actor step, often stabilizing learning in high-variance settings.
Example 3.2 (REINFORCE with a Learned Value Baseline for Cart-Pole) Consider the same cart-pole balancing task in Example 3.1. We use minibatch REINFORCE with a learned value baseline (batch size \(50\)), the algorithm described above.
Fig. 3.5 shows the learning curve. The algorithm is able to steadily increase the per-episode returns.
Fig. 3.6 shows a rollout of the system trajectory under the learned policy.
You can play with the code here.

Figure 3.5: Learning curve (Minibatch REINFORCE with a Learned Value Baseline).

Figure 3.6: Policy rollout (Minibatch REINFORCE with a Learned Value Baseline).
3.3 Actor–Critic Methods
Actor–critic (AC) algorithms marry policy gradients (the actor) with value function learning (the critic). The critic reduces variance by supplying low-noise estimates of action quality (values or advantages), while the actor updates the policy using these estimates. In contrast to pure Monte Carlo baselines, actor–critic bootstraps from its own predictions, enabling online, incremental, and often more sample-efficient learning.
3.3.1 Anatomy of an Actor–Critic
- Actor (policy): a differentiable policy \(\pi_\theta(a\mid s)\).
- Critic (value): an approximator for \(V_\phi(s)\), \(Q_\psi(s,a)\), or directly the advantage \(A_\eta(s,a)\).
- Update coupling: the actor ascends a baseline-subtracted log-likelihood objective using advantage-like targets supplied by the critic.
3.3.2 On-Policy Actor–Critic with TD(0)
We first learn a state value function \(V_\phi(s)\) with a one-step bootstrapped TD(0) target: \[ \delta_t \;\equiv\; r_t + \gamma\,V_\phi(s_{t+1}) - V_\phi(s_t), \qquad \mathcal{L}_V(\phi) \;=\; \frac12\,\delta_t^{\,2}. \tag{3.31} \] If \(V_\phi \approx V^\pi\), then \(\mathbb{E}[\delta_t\mid s_t,a_t]\approx A^\pi(s_t,a_t)\), so \(\delta_t\) serves as a low-variance advantage target for the actor: \[ \widehat{\nabla_\theta J} \;=\; \frac{1}{|\mathcal{B}|} \sum_{(s_t,a_t)\in \mathcal{B}} \nabla_\theta \log\pi_\theta(a_t\mid s_t)\,\underbrace{\delta_t}_{\text{advantage target}}. \tag{3.32} \] (Practical: normalize \(\{\delta_t\}_{\mathcal{B}}\) to mean \(0\) and unit variance within a batch; clip gradients for stability.)
Inputs: policy \(\pi_\theta(a\mid s)\), value \(V_\phi(s)\), discount \(\gamma\in[0,1)\), stepsizes \(\alpha_\theta,\alpha_\phi>0\), rollout length \(K\), minibatch size \(|\mathcal{B}|\).
For iterations \(k=0,1,2,\dots\):
Collect on-policy rollouts. Run \(\pi_\theta\) for \(K\) steps (optionally across parallel envs), storing transitions \(\{(s_t,a_t,r_t,s_{t+1}\}\).
Compute TD errors. For each transition, compute the TD error \[ \delta_t \leftarrow r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t). \]
Critic update (value). Minimize \(\sum_{t\in\mathcal{B}} \frac12\,\delta_t^{\,2}\): perform multiple steps of \[ \phi \leftarrow \phi - \alpha_\phi \,\nabla_\phi \Big(\frac{1}{|\mathcal{B}|}\sum_{t\in\mathcal{B}}\frac12\,\delta_t^{\,2}\Big). \]
Actor advantages. Set \(\widehat{A}_t \leftarrow \delta_t\) (optionally normalize over \(\mathcal{B}\)).
Actor update (policy gradient). \[ \theta \leftarrow \theta + \alpha_\theta \,\frac{1}{|\mathcal{B}|}\sum_{t\in\mathcal{B}} \nabla_\theta\log\pi_\theta(a_t\mid s_t)\,\widehat{A}_t. \]
Repeat from step 1.
We apply the on-policy actor-critic algorithm to the cart-pole balancing task.
Example 3.3 (Actor–Critic with One-Step Bootstrap for Cart-Pole) Consider the same cart-pole balancing control task as before, and this time apply the on-policy actor-critic with one-step bootstrap.
Fig. 3.7 shows the learning curve.
Fig. 3.8 shows an example rollout of the policy.
You can play with the code here.
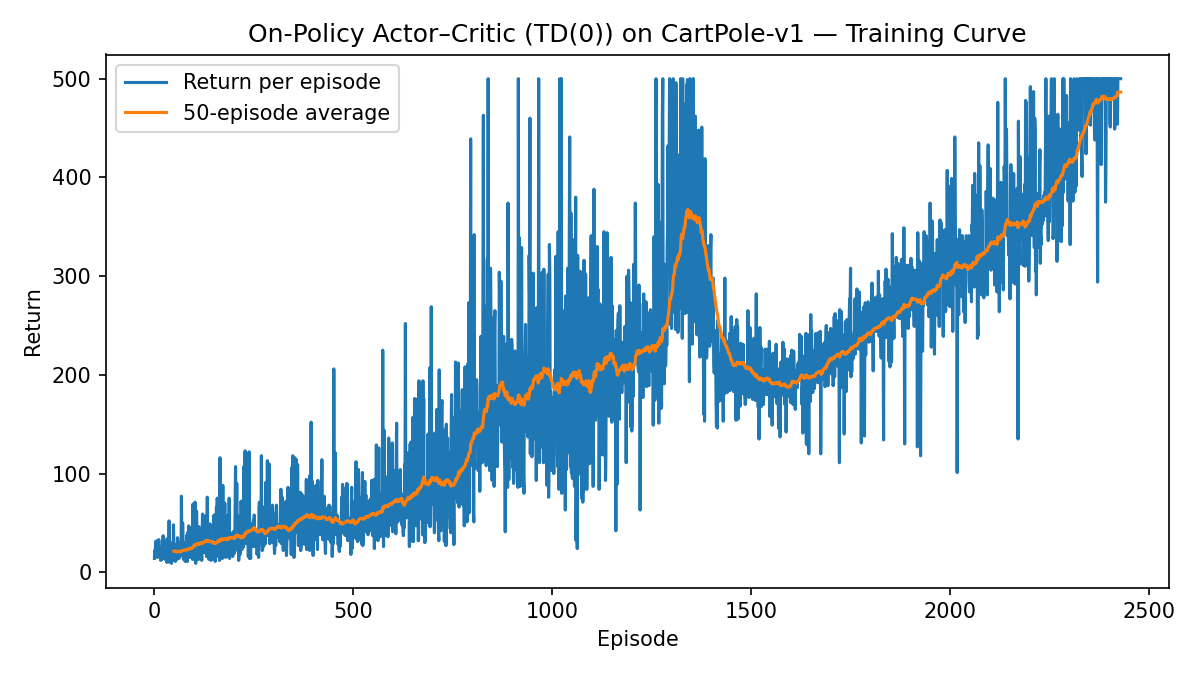
Figure 3.7: Learning curve (Actor–Critic with One-Step Bootstrap).
Figure 3.8: Policy rollout (Actor–Critic with One-Step Bootstrap).
3.3.3 Generalized Advantage Estimation (GAE)
In REINFORCE with a learned value baseline (Section 3.2.4.4), we used the full Monte Carlo return \(g_t\) as the target for value function approximation; while in on-policy Actor-Critic with TD(0) (Section 3.3.2), we used the one-step bootstrap return \(r_t + \gamma V_\phi (s_{t+1})\) as the target for value function estimation.
Recall in policy evaluation (Section 2.1.1), we have introduced a spectrum of methods that sit in between Monte Carlo and TD(0): they are methods that leverage the \(n\)-step bootstrap return that balance bias and variance. (Section 2.1.1.3 and 2.1.1.4).
In particular, recall the definition of an \(n\)-step bootstrap return \[\begin{equation} g^{(n)}_t = \sum_{k=0}^{n-1} \gamma^k r_{t+k} \;+\; \gamma^{n}\,V_\phi(s_{t+n}), \tag{3.33} \end{equation}\] where \(V_\phi\) denotes the approximate value function. The \(\lambda\)-return (with \(\lambda \in [0,1]\)) performs a convex combination of all the \(n\)-step returns \[\begin{equation} g^{(\lambda)}_t = (1-\lambda)\sum_{n=1}^{\infty} \lambda^{n-1} \, g^{(n)}_t. \tag{3.34} \end{equation}\]
The Generalized Advantage Estimation (GAE) algorithm (Schulman, Moritz, et al. 2015) is an Actor-Critic type of policy gradient method that leverages the \(\lambda\)-return as the target for fitting the critic (i.e., the approximate value function).
GAE-\(\lambda\) Advantage. Start from the TD residual \[ \delta_t \;=\; r_t + \gamma\,V_\phi(s_{t+1}) - V_\phi(s_t), \qquad \tag{3.35} \] and define the GAE-\(\lambda\) advantage as the exponentially-weighted sum of future TD residuals: \[ \widehat{A}^{(\lambda)}_t \;=\; \sum_{\ell=0}^{T-1-t} (\gamma\lambda)^\ell \,\delta_{t+\ell}. \qquad \tag{3.36} \] This admits an efficient backward recursion: \[ \widehat{A}^{(\lambda)}_t \;=\; \delta_t \;+\; \gamma\lambda\,\widehat{A}^{(\lambda)}_{t+1}, \quad \widehat{A}^{(\lambda)}_{T}=0 \text{ (at terminal).} \qquad \tag{3.37} \]
From Advantage to Return. A key identity (obtained by expanding the sum of TD residuals and grouping terms) is \[ \sum_{\ell=0}^{\infty} (\gamma\lambda)^\ell \,\delta_{t+\ell} \;=\; \Big(1-\lambda\Big)\sum_{n=1}^{\infty}\lambda^{n-1}\Big(g^{(n)}_t - V_\phi(s_t)\Big). \tag{3.38} \] The left-hand side is the GAE-\(\lambda\) advantage, and the right-hand side is \(g^{(\lambda)}_t - V_{\phi}(s_t)\). Therefore, \[ \widehat{A}^{(\lambda)}_t \;=\; g^{(\lambda)}_t \;-\; V_\phi(s_t), \qquad\text{and hence}\qquad g_t^{(\lambda)} \;=\; \widehat{A}^{(\lambda)}_t + V_\phi(s_t). \] In GAE, we use \[ \widehat{V}^{\,\text{targ}}_t \;=\; \widehat{A}^{(\lambda)}_t \;+\; V_\phi(s_t), \tag{3.39} \] as the target for fitting \(V_\phi\).
GAE Policy Gradient. The true on-policy policy gradient can be written as \[ \nabla_\theta J(\theta) \;=\; \mathbb{E}\!\left[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,A^\pi(s_t,a_t)\right]. \qquad \tag{3.40} \] An estimator remains unbiased if we replace \(A^\pi\) by any \(\widehat{A}\) satisfying \[ \mathbb{E}\!\left[\widehat{A}_t \,\middle|\, s_t,a_t\right] \;=\; A^\pi(s_t,a_t). \qquad \tag{3.41} \]
When the critic is exact, \(V_\phi\equiv V^\pi\), each \(n\)-step bootstrap return has expectation \[ \mathbb{E}\!\left[g^{(n)}_t \,\middle|\, s_t,a_t\right] \;=\; Q^\pi(s_t,a_t), \] so by linearity and (3.34), \[ \mathbb{E}\!\left[g^{(\lambda)}_t \,\middle|\, s_t,a_t\right] \;=\; Q^\pi(s_t,a_t). \] Using \(\widehat{A}^{(\lambda)}_t = g^{(\lambda)}_t - V^\pi(s_t)\) gives \[ \mathbb{E}\!\left[\widehat{A}^{(\lambda)}_t \,\middle|\, s_t,a_t\right] \;=\; Q^\pi(s_t,a_t) - V^\pi(s_t) \;=\; A^\pi(s_t,a_t), \] which satisfies (3.41). Plugging \(\widehat{A}^{(\lambda)}_t\) into (3.40) thus yields an unbiased policy-gradient estimator.
The pseudocode for GAE is presented below.
Inputs: policy \(\pi_\theta(a\mid s)\), value \(V_\phi(s)\), discount \(\gamma\in[0,1)\), GAE parameter \(\lambda\in[0,1]\); stepsizes \(\alpha_\theta,\alpha_\phi>0\); rollout length \(T\); minibatch size \(B\).
For iterations \(k=0,1,2,\dots\):
Collect rollouts. Run \(\pi_\theta\) to collect \(B\) trajectories and each trajectory has \(T\) steps , storing \((s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\).
Values & residuals. Compute \[ v_t\!\leftarrow\!V_\phi(s_t), \ \ v_{t+1}\!\leftarrow\!V_\phi(s_{t+1}),\ \ m_t\!\leftarrow\!1-\mathrm{done}_t, \ \ \delta_t \leftarrow r_t + \gamma m_t v_{t+1} - v_t. \]
Backward GAE. Set \(\widehat{A}_{T}\!\leftarrow\!0\), and for \(t=T-1\) to \(0\) do:
\[ \widehat{A}_t \leftarrow \delta_t + \gamma\lambda m_t \widehat{A}_{t+1}. \] (Optionally normalize \(\{\widehat{A}_t\}\) within the minibatch.)Critic target (\(\lambda\)-return). Set critic target \[ \widehat{V}^{\,\text{targ}}_t \leftarrow \widehat{A}_t + v_t \;\;(=g^{(\lambda)}_t). \]
Critic update. Gradient descent: \[ \phi \leftarrow \phi - \alpha_\phi \nabla_\phi \frac{1}{ B }\sum_{t }\big(V_\phi(s_t)-\widehat{V}^{\,\text{targ}}_t\big)^2. \]
(Often take several critic steps here.)Actor update. Gradient ascent \[ \theta \leftarrow \theta + \alpha_\theta \frac{1}{ B }\sum_{t } \nabla_\theta \log \pi_\theta(a_t\mid s_t)\,\widehat{A}_t. \]
The next example applies GAE to the cart-pole balancing problem.
Example 3.4 (GAE for Cart-Pole Balancing) Fig. 3.9 shows the learning curve using Actor-Critic with GAE and Fig. 3.10 shows a sample rollout of the trained policy.
The Python code can be found here.
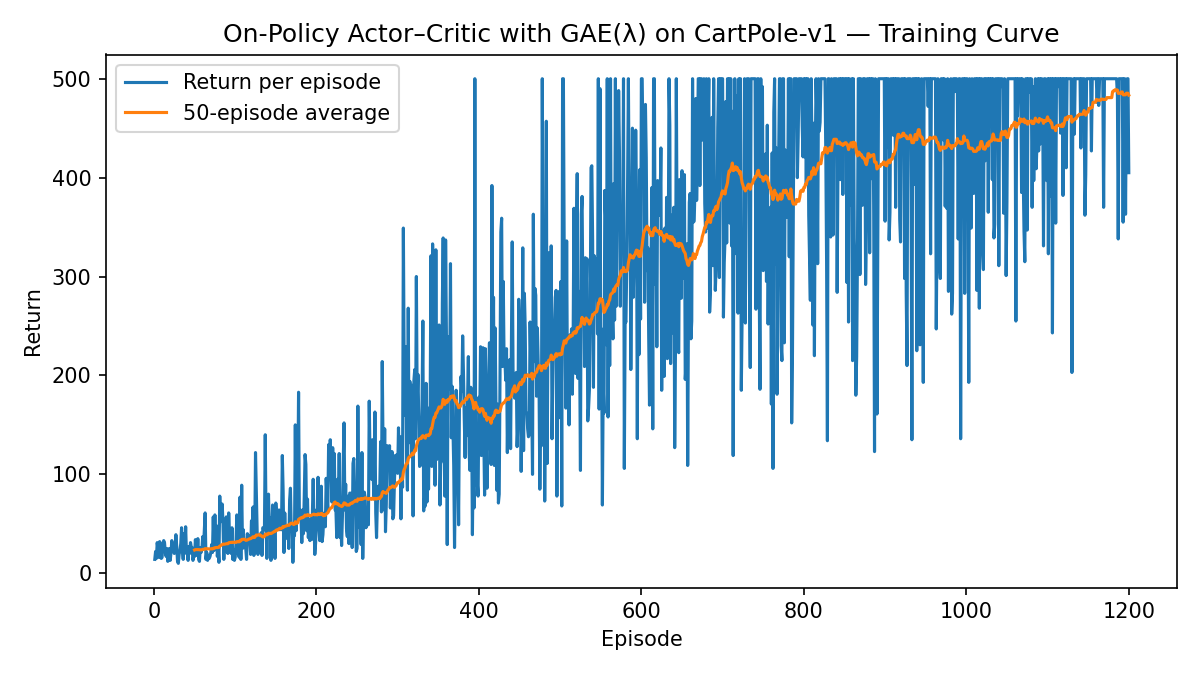
Figure 3.9: Learning curve (Actor–Critic with GAE).
Figure 3.10: Policy rollout (Actor–Critic with GAE).
3.3.4 Off-Policy Actor–Critic
On-policy actor–critic discards data after a single update. Off-policy methods decouple the behavior policy (that collects data) from the target policy (that we improve), enabling replay buffers and better sample efficiency.
Off-Policy Policy Gradient. When data come from a behavior policy \(b\neq \pi_\theta\), define the per-decision likelihood ratio \[ \rho_t \;=\; \frac{\pi_\theta(a_t\mid s_t)}{b (a_t\mid s_t)}. \qquad \tag{3.42} \] A basic off-policy policy gradient with an advantage target \(\widehat{A}_t\) is \[\begin{equation} \widehat{\nabla_\theta J} \;=\; \mathbb{E}\!\left[\rho_t\,\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,\widehat{A}_t\right]. \tag{3.43} \end{equation}\] In practice we often clip the ratio to control variance: \[ \bar\rho_t \;=\; \min\{\rho_t,\;c\}, \quad c\!\ge\!1, \qquad \widehat{\nabla_\theta J} \approx \mathbb{E}\!\left[\bar\rho_t\,\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,\widehat{A}_t\right]. \] Clipping introduces small bias but usually reduces variance.
Off-policy Critic. A convenient choice is an action-value critic \(Q_\psi(s,a)\) trained with an expected SARSA style target under the current \(\pi_\theta\): \[ \begin{split} y_t & = r_t \;+\; \gamma \, \mathbb{E}_{a'\sim\pi_\theta(\cdot\mid s_{t+1})}\!\left[Q_{\bar\psi}(s_{t+1},a')\right], \\ \psi & \leftarrow \arg\min_\psi \;\mathbb{E}\big[(Q_\psi(s_t,a_t)-y_t)^2\big], \end{split} \tag{3.44} \] where \(Q_{\bar\psi}\) is a target network used to stabilize bootstrapping (i.e., mitigate the deadly triad). For discrete actions, the expectation is an exact sum \(\sum_{a'}\pi_\theta(a'\mid s')Q_{\bar\psi}(s',a')\); for continuous, we approximate the expectation with a few samples \(a'\!\sim\!\pi_\theta(\cdot\mid s')\).
Advantage. Given \(Q_\psi\), we can estimate the advantage by \[ \widehat{A}_t \;=\;Q_\psi(s_t,a_t) \;-\; V_\psi(s_t), \quad V_\psi(s) \;\equiv\; \mathbb{E}_{a\sim\pi_\theta(\cdot\mid s)}[Q_\psi(s,a)]. \qquad \tag{3.45} \] Again, for discrete actions, we can compute \(V_\psi\) exactly; for continuous actions, we approximate using a few samples.
Pseudocode for off-policy actor-critic is presented below.
Inputs: target policy \(\pi_\theta\), Q-critic \(Q_\psi\) (and target \(Q_{\bar\psi}\)), discount \(\gamma\), stepsizes \(\alpha_\theta,\alpha_\psi\), replay buffer \(\mathcal{D}\), IS clip \(c\ge 1\), minibatch size \(B\).
Initialize: \(\bar\psi\leftarrow\psi\). Behavior policy \(b\) can be \(\pi_\theta\) with exploration (e.g., \(\varepsilon\)-greedy).
For iterations \(k=0,1,2,\dots\):
Interact & store. Use \(b\) to step the env and append to \(\mathcal{D}\) tuples \((s_t,a_t,r_t,s_{t+1},\mathrm{done}_t,\;p_t^b)\), where \(p_t^b=b(a_t\mid s_t)\) (store this to compute \(\rho_t\)).
Sample minibatch Sample transitions \(\{(s,a,r,s',d,p^\mu)\}_{i=1}^B\) from the replay buffer \(\mathcal{D}\).
Critic target (expected SARSA).
- Compute \(\pi_\theta(a'\mid s')\) and \(Q_{\bar\psi}(s',a')\).
- Set \(y \leftarrow r + \gamma(1-\mathrm{done}_t)\sum_{a'} \pi_\theta(a'\mid s')\,Q_{\bar\psi}(s',a')\). (for continuous actions: perform sample average)
Critic update. \[ \psi \leftarrow \psi - \alpha_\psi \nabla_\psi\frac{1}{B}\sum_{i=1}^B\big(Q_\psi(s_i,a_i)-y_i\big)^2. \] (Optionally clip gradients; perform multiple critic steps.)
Actor advantage.
- Compute \(V_\psi(s)=\sum_{a}\pi_\theta(a\mid s)\,Q_\psi(s,a)\) (or sample-average for continuous actions).
- Set \(\widehat{A}=Q_\psi(s,a)-V_\psi(s)\); optionally normalize \(\widehat{A}\) within the batch.
- Compute \(V_\psi(s)=\sum_{a}\pi_\theta(a\mid s)\,Q_\psi(s,a)\) (or sample-average for continuous actions).
Importance ratios (clipped). \[ \rho \leftarrow \frac{\pi_\theta(a\mid s)}{p^b},\qquad \bar\rho \leftarrow \min\{\rho,\;c\}. \]
Actor update. \[ \theta \leftarrow \theta + \alpha_\theta\, \frac{1}{B}\sum_{i=1}^B \bar\rho_i \,\nabla_\theta \log \pi_\theta(a_i\mid s_i)\,\widehat{A}_i. \]
Target network (moving average). \[ \bar\psi \leftarrow \tau\,\psi + (1-\tau)\,\bar\psi. \]
Notes & Variants.
- Unbiased vs. biased: Without clipping and with a correct critic/advantage, (3.43) is unbiased; clipping \(\bar\rho\) adds bias but improves variance.
- Critic options: You can learn \(V_\phi\) instead of \(Q_\psi\) using off-policy TD with IS; using \(Q\) with an expected SARSA target avoids IS in the critic while keeping evaluation under \(\pi_\theta\).
- Behavior refresh: Periodically update \(b\) toward \(\pi_\theta\) (reduce exploration) to keep ratios well-behaved.
The next example applies off-policy actor-critic to cart-pole balancing.
Example 3.5 (Off-Policy Actor-Critic for Cart-Pole Balancing) Fig. 3.11 shows the learning curve of applying off-policy actor-critic to cart-pole balancing.
Fig. 3.12 shows a sample rollout of the learned policy.
The Python code can be found here.
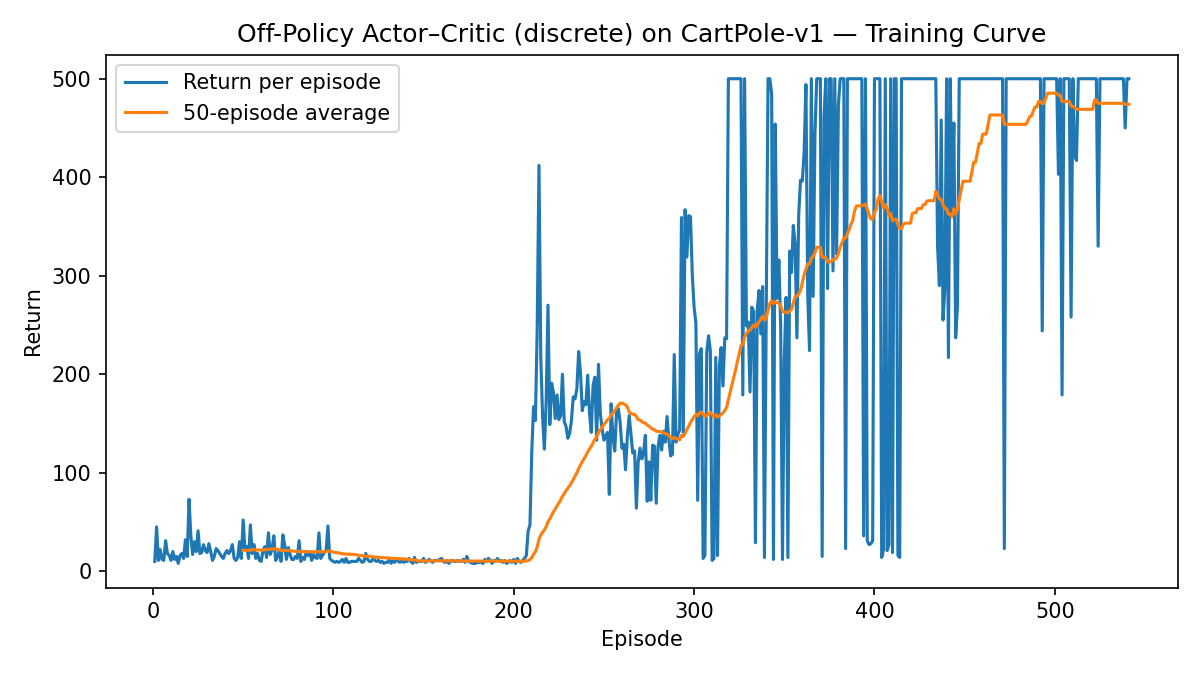
Figure 3.11: Learning curve (Off-Policy Actor–Critic).

Figure 3.12: Policy rollout (Off-Policy Actor–Critic).
The next example applies off-policy actor-critic to a control problem with a continuous action space.
Example 3.6 (Off-Policy Actor-Critic for Inverted Pendulum) Consider the Inverted Pendulum problem illustrated in Fig. 3.13. The state of the pendulum is \(s = (\theta, \dot{\theta})\), or equivalently, \(s = (x, y, \dot{\theta})\) with \(x = \cos(\theta), y = \sin(\theta)\). The action space is continuous: \(\tau \in \mathcal{A} = [-2,2]\).
The dynamics of the pendulum is specified by Gym, and the reward is \[ R(s,\tau) = -(\theta^2 + 0.1 \dot{\theta}^2 + 0.001 \tau^2). \] The episode truncates at \(200\) time steps.
Figure 3.13: Illustration of Inverted Pendulum in Gym.
Fig. 3.14 shows the learning curve of applying off-policy actor-critic to the pendulum problem.
Fig. 3.15 shows a sample rollout of the learned policy.
You can find the Python code here.
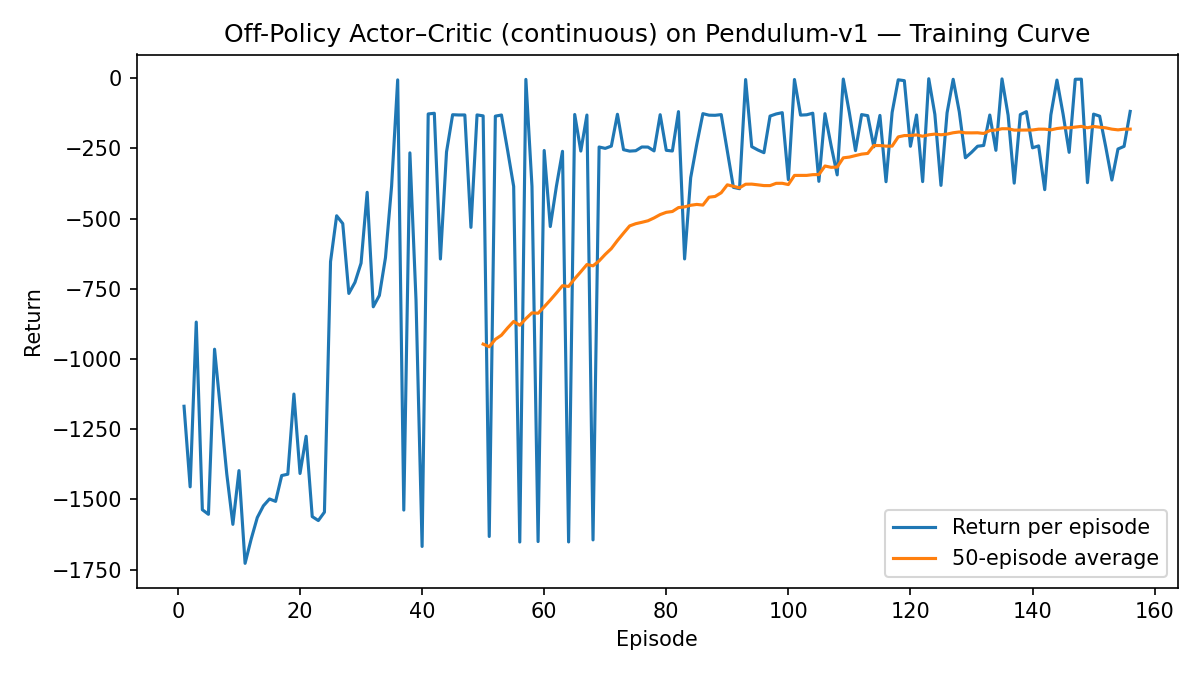
Figure 3.14: Learning curve (Off-Policy Actor-Critic).




Figure 3.15: Policy rollout (Off-Policy Actor-Critic).
3.4 Advanced Policy Gradients
3.4.1 Revisiting Generalized Policy Iteration
Recall from Chapter 2 that generalized policy iteration (GPI) extends tabular policy iteration (with known dynamics) to unknown-dynamics settings. At a high level, GPI iterates over policies; at iteration \(k\) it performs:
Policy evaluation. Use the current policy \(\pi_k\) to generate \(N\) trajectories and estimate either the \(Q\)-function \(\hat Q^{\pi_k}(s,a)\) or the advantage function \(\hat A^{\pi_k}(s,a)\), using function approximation. This can be done, for example, with the GAE algorithm introduced in Section 3.3.3, and is the “critic” in the Actor–Critic family of methods.
Policy improvement. Construct a new policy \(\pi_{k+1}\) that (approximately) prefers actions deemed better by \(\hat Q^{\pi_k}\) or \(\hat A^{\pi_k}\): \[ \pi_{k+1}(s) \approx \arg\max_a \hat Q^{\pi_k}(s,a) \;=\; \arg\max_a \hat A^{\pi_k}(s,a). \] In policy gradients, we approximate \(\arg\max_a \hat A^{\pi_k}(s,a)\) via gradient ascent in \(a\), i.e., using \[\begin{equation} \nabla_\theta J(\theta) = \frac{1}{1-\gamma}\, \mathbb{E}_{s \sim d_{\pi_k},\, a \sim \pi_k} \big[\nabla_\theta \log \pi_\theta(a \mid s)\, \hat A^{\pi_k}(s,a)\big]. \tag{3.46} \end{equation}\]
A key observation is that we use an advantage estimate obtained from data generated by \(\pi_k\) (the old policy) to produce a new policy. In the tabular case, this improvement step guarantees monotonic improvement of \(\pi_{k+1}\) over \(\pi_k\), because the evaluation produces a value (or advantage) estimate over the entire state space. In continuous state spaces, this no longer holds: we typically can only obtain an advantage estimate that is accurate along the state–action distribution induced by \(\pi_k\) rather than globally over \(\mathcal{S}\times\mathcal{A}\). (If, however, we use off-policy data, the expectation here can be different.)
The question “how much better is \(\pi_{k+1}\) than \(\pi_k\)?” motivates a relation between the performances of two policies that explicitly accounts for distribution shift.
3.4.2 Performance Difference Lemma
The following performance difference lemma (PDL) expresses the return gap between two policies in terms of the (old) policy’s advantage and the (new) policy’s state-action visitation:
Theorem 3.8 (Performance Difference Lemma) Let \(\pi\) and \(\pi'\) be two stationary policies in a discounted MDP with \(\gamma\in[0,1)\). Then \[\begin{equation} J(\pi') - J(\pi) \;=\; \frac{1}{1-\gamma}\; \mathbb{E}_{s\sim d^{\pi'},\,a\sim \pi'}\!\left[A^{\pi}(s,a)\right], \qquad \tag{3.47} \end{equation}\] where \(d^{\pi}(s)=(1-\gamma)\sum_{t=0}^\infty \gamma^t\,\Pr_{\pi}(s_t=s)\) is the (discounted) state-visitation distribution generated by policy \(\pi\) and \(A^\pi=Q^\pi-V^\pi\) is the advantage.
Interpretation. The performance difference lemma highlights distribution shift: the advantage is evaluated under policy \(\pi\), while the expectation is taken over the state–action distribution induced by \(\pi'\). In policy gradients, when performing a step using (3.46), we are approximately maximizing the surrogate \[ \mathcal{L}_{\pi}(\pi') := \frac{1}{1-\gamma}\; \mathbb{E}_{s\sim d^{\pi},\,a\sim \pi'}[A^{\pi}(s,a)], \] where the state distribution is \(d_\pi\), not \(d_{\pi'}\). To guarantee improvement, we want this surrogate to reflect the true gain \(J(\pi')-J(\pi)\). The two coincide when \(d^{\pi'} \approx d^{\pi}\). Hence, keep \(\pi'\) close to \(\pi\) so state visitation does not change dramatically, making the surrogate reliable (to some extent, off-policy versions of actor–critic aim to achieve this). This “stay local” principle underpins TRPO, NPG, and PPO.
3.4.3 Trust Region Constraint
How to enforce the new policy \(\pi_{\theta_{k+1}}\) to be close to the old policy \(\pi_{\theta_{k}}\)?
KL Divergence. The Kullback–Leibler (KL) divergence is a type of statistical distance: a measure of how much an approximating probability distribution \(Q\) is different from a true probability distribution \(P\). Formally, let \(P\) and \(Q\) be two probability distributions supported on \(\mathcal{X}\), the KL divergence between \(P\) and \(Q\) is \[\begin{equation} D_{\mathrm{KL}}(P \Vert Q) = \sum_{x \in \mathcal{X}} P(x) \log \left( \frac{P(x)}{Q(x)} \right) = \mathbb{E}_{x \sim P(x)}\left[ \log \left( \frac{P(x)}{Q(x)} \right) \right]. \tag{3.48} \end{equation}\] For example, when \(P = Q\), we have \(D_{\mathrm{KL}}(P \Vert Q) = 0\). Indeed, \(D_{\mathrm{KL}}(P \Vert Q) \geq 0\) and the equality holds if and only if \(P = Q\).
Trust Region Constraint. We now augment the usual policy optimization problem with a trust region constraint defined by the KL divergence. In particular, we wish to improve the current policy \(\pi_{\theta_k}\) locally by maximizing a surrogate advantage objective while constraining the expected KL divergence from the old policy. This keeps the new policy \(\pi_{\theta}\) close to \(\pi_{\theta_k}\), so the surrogate built under \(d^{\pi_{\theta_k}}\) remains predictive of true improvement.
Formally, let \(\theta_k\) denote the current policy parameters. Define the importance ratio \[ \rho_\theta(s,a)=\frac{\pi_\theta(a\mid s)}{\pi_{\theta_k}(a\mid s)}. \] We aim to maximize the on-policy surrogate \[\begin{equation} L_{\theta_k}(\theta) \;=\; \mathbb{E}_{s\sim d^{\pi_{\theta_k}},\,a\sim \pi_{\theta_k}} \!\big[\rho_\theta(s,a)\,\widehat{A}^{\,\pi_{\theta_k}}(s,a)\big], \qquad \tag{3.49} \end{equation}\] subject to an expected KL constraint measured under the old state distribution: \[\begin{equation} \bar D_{\mathrm{KL}}(\theta_k\,\|\,\theta) \;:=\; \mathbb{E}_{s\sim d^{\pi_{\theta_k}}} \!\left[ D_{\mathrm{KL}}\!\big(\pi_{\theta_k}(\cdot\mid s)\,\|\,\pi_{\theta}(\cdot\mid s)\big) \right] \;\le\;\delta, \qquad \tag{3.50} \end{equation}\] with a small radius \(\delta>0\). In summary, we are now interested in the following constrained policy optimization problem: \[\begin{equation} \begin{split} \max_\theta & \quad L_{\theta_k}(\theta) \\ \text{subject to} & \quad \bar D_{\mathrm{KL}}(\theta_k\,\|\,\theta) \leq \delta. \end{split} \tag{3.51} \end{equation}\]
3.4.4 Natural Policy Gradient
The natural policy gradient method (Kakade 2001) can be seen as first performing a linear approximation to the objective of (3.51) and a quadratic approximation to the constraint of (3.51), and then solve the resulting approximate problem in closed form.
Leading-Order Approximation. To maximize the surrogate \(L_{\theta_k}(\theta)\) in (3.49) subject to the KL trust-region constraint (3.50), we linearize the surrogate around \(\theta_k\) and quadratically approximate the KL trust region constraint. This leads to the following convex quadratic program (QP) \[\begin{equation} \max_{\Delta\theta}\ \ g^\top \Delta\theta \quad\text{s.t.}\quad \frac{1}{2}\,\Delta\theta^\top F(\theta_k)\,\Delta\theta \;\le\; \delta, \tag{3.52} \end{equation}\] where \[\begin{equation} g \;=\; \nabla_\theta L_{\theta_k}(\theta)\big|_{\theta=\theta_k} = \mathbb{E}_{s\sim d^{\pi_{\theta_k}},\,a\sim \pi_{\theta_k}(\cdot\mid s)} \big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\,\widehat{A}(s,a)\big] \tag{3.53} \end{equation}\] is the policy gradient, and \[\begin{equation} F(\theta_k) \;=\; \mathbb{E}_{s\sim d^{\pi_{\theta_k}},\,a\sim \pi_{\theta_k}(\cdot\mid s)} \big[\nabla_\theta \log \pi_{\theta_k}(a \mid s)\,\nabla_\theta \log \pi_{\theta_k}(a\mid s)^\top\big] \tag{3.54} \end{equation}\] is the (empirical) Fisher information of the policy under the old distribution. See a proof in Section 3.4.5.
One can show that the QP (3.52) has a closed-form solution: \[\begin{equation} p_{\text{NPG}} \;=\; F(\theta_k)^{-1}\, g, \qquad \Delta\theta_{\text{NPG}} \;=\; \sqrt{\frac{2\delta}{g^\top F(\theta_k)^{-1} g}}\;\;p_{\text{NPG}}, \tag{3.55} \end{equation}\] where \(p_{\text{NPG}}\) is called the natural policy gradient, for the reason that the usual policy gradient \(g\) is pre-multiplied by \(F(\theta_k)^{-1}\), which contains the second-order curvature of the KL constraint. In practice, \(p_{\text{NPG}}\) is computed with conjugate gradient (CG) using Fisher–vector products; no matrices are formed. In (3.55), \[ \alpha = \sqrt{\frac{2\delta}{g^\top F(\theta_k)^{-1} g}} = \sqrt{ \frac{2\delta}{p^\top_{\text{NPG}} F(\theta_k) p_{\text{NPG}} } } \] is often called the trust-region step size.
The following pseudocode implements NPG with GAE as the critic.
Inputs: initial policy \(\theta_0\); value/critic \(\phi_0\); discount \(\gamma\); GAE parameter \(\lambda\); KL radius \(\delta\) (or learning rate \(\eta\)); CG iterations \(K_{\mathrm{cg}}\); (optional) damping \(\xi>0\).
For iterations \(k=0,1,2,\dots\):
Collect rollouts (on-policy). Run \(\pi_{\theta_k}\) to obtain a batch \(\{(s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\}_{t=1}^N\); cache \(\log \pi_{\theta_k}(a_t\mid s_t)\).
Critic / advantages (GAE).
Compute TD residuals \(\delta_t = r_t + \gamma(1-\mathrm{done}_t)V_\phi(s_{t+1}) - V_\phi(s_t)\);
backward recursion \(\widehat{A}_t = \delta_t + \gamma\lambda(1-\mathrm{done}_t)\widehat{A}_{t+1}\), with \(\widehat{A}_{T}=0\);
(optionally) standardize \(\widehat{A}\); set value targets \(\widehat{V}^{\,\text{targ}}_t=\widehat{A}_t+V_\phi(s_t)\).Value update. Fit \(V_\phi\) by minimizing \(\sum_t (V_\phi(s_t)-\widehat{V}^{\,\text{targ}}_t)^2\) (one or several epochs).
Surrogate gradient.
\[ g \;=\; \frac{1}{N} \sum_{t} \nabla_\theta \log \pi_{\theta_k}(a_t \mid s_t )\,\widehat{A}_t . \]Fisher–vector product (FvP). Define the empirical KL \(\bar D_{\mathrm{KL}}(\theta_k\,\|\,\theta)\). Implement \(v\mapsto Fv\) as the Hessian–vector product of \(\bar D_{\mathrm{KL}}\) at \(\theta_k\) (optionally use damping \(F \leftarrow F+\xi I\) to make sure \(F\) is positive definite).
Conjugate gradient (CG). Approximately solve \((F)\,p = g\) to obtain \(p_{\text{NPG}}\approx F^{-1}g\).
Step size.
- Trust-region scaling: set
\(\alpha \leftarrow \sqrt{\frac{2\delta}{p^\top_{\text{NPG}} F p_{\text{NPG}}}}\) and update \(\theta_{k+1} \leftarrow \theta_k + \alpha p_{\text{NPG}}\).
- Fixed-rate natural step: choose \(\eta>0\) and set \(\theta_{k+1} \leftarrow \theta_k + \eta p_{\text{NPG}}\) (monitor empirical KL for safety).
- Trust-region scaling: set
\(\alpha \leftarrow \sqrt{\frac{2\delta}{p^\top_{\text{NPG}} F p_{\text{NPG}}}}\) and update \(\theta_{k+1} \leftarrow \theta_k + \alpha p_{\text{NPG}}\).
3.4.5 Proof of Fisher Information
Let the expected KL trust-region constraint (measured under the old policy’s state distribution) be \[ \bar D_{\mathrm{KL}}(\theta_k\!\parallel\!\theta) \;:=\; \mathbb{E}_{s\sim d^{\pi_{\theta_k}}} \Big[ D_{\mathrm{KL}}\!\big(\pi_{\theta_k}(\cdot\mid s)\,\|\,\pi_\theta(\cdot\mid s)\big) \Big]. \] Write \(\theta=\theta_k+\Delta\theta\) and define, for a fixed state \(s\), \[ f_s(\theta) \;=\; D_{\mathrm{KL}}\!\big(\pi_{\theta_k}(\cdot\mid s)\,\|\,\pi_\theta(\cdot\mid s)\big) = \mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)} \big[\log \pi_{\theta_k}(a\mid s) - \log \pi_\theta(a\mid s)\big]. \] We will show that the second-order Taylor expansion of \(\bar D_{\mathrm{KL}}\) around \(\theta_k\) is \[ \bar D_{\mathrm{KL}}(\theta_k\!\parallel\!\theta_k+\Delta\theta) \;=\; \frac{1}{2}\,\Delta\theta^\top \underbrace{ \mathbb{E}_{s\sim d^{\pi_{\theta_k}},\,a\sim \pi_{\theta_k}(\cdot\mid s)} \!\big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\,\nabla_\theta \log \pi_{\theta_k}(a\mid s)^\top\big] }_{F(\theta_k)\ \text{(Fisher information)}} \,\Delta\theta \;+\; \mathcal{O}(\|\Delta\theta\|^3). \]
Step 1: Zeroth- and first-order terms vanish at \(\theta=\theta_k\). For each \(s\), \[ f_s(\theta_k) = D_{\mathrm{KL}}\!\big(\pi_{\theta_k}\,\|\,\pi_{\theta_k}\big)=0. \] The gradient (holding the expectation under \(\pi_{\theta_k}\)) is \[ \nabla_\theta f_s(\theta) = -\mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)}\big[\nabla_\theta \log \pi_\theta(a\mid s)\big]. \] Evaluating at \(\theta=\theta_k\), \[ \begin{split} \nabla_\theta f_s(\theta_k) & = -\mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)}\big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\big] \\ & = -\sum_a \pi_{\theta_k}(a\mid s)\,\nabla_\theta \log \pi_{\theta_k}(a\mid s) = -\nabla_\theta \sum_a \pi_{\theta_k}(a\mid s) = 0, \end{split} \] using the normalization \(\sum_a \pi_{\theta_k}(a\mid s)=1\). Hence both the value and the first-order term are zero.
Step 2: The Hessian equals the (per-state) Fisher information. The Hessian of \(f_s\) is \[ \nabla_\theta^2 f_s(\theta) = -\mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)}\big[\nabla_\theta^2 \log \pi_\theta(a\mid s)\big]. \] At \(\theta=\theta_k\), apply the information identity (a.k.a. Bartlett identity): \[ -\mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)}\big[\nabla_\theta^2 \log \pi_{\theta_k}(a\mid s)\big] = \mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)} \big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\, \nabla_\theta \log \pi_{\theta_k}(a\mid s)^\top\big]. \]
Proof sketch of the identity: start from \(\sum_a \pi_\theta(a\mid s)=1\), differentiate once to get \(\mathbb{E}_{a\sim \pi_\theta}[\nabla\log\pi_\theta]=0\); differentiate again and use the product rule to obtain \(\mathbb{E}_{a\sim \pi_\theta}[\nabla^2\log\pi_\theta + (\nabla\log\pi_\theta)(\nabla\log\pi_\theta)^\top]=0\).
Thus, \[ \nabla_\theta^2 f_s(\theta_k) = \mathbb{E}_{a\sim \pi_{\theta_k}(\cdot\mid s)} \big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\,\nabla_\theta \log \pi_{\theta_k}(a\mid s)^\top\big] \;=:\; F_s(\theta_k). \]
Step 3: Second-order Taylor expansion and averaging over states. For each \(s\), \[ f_s(\theta_k+\Delta\theta) = \frac{1}{2}\,\Delta\theta^\top F_s(\theta_k)\,\Delta\theta \;+\; \mathcal{O}(\|\Delta\theta\|^3). \] Taking expectation over \(s\sim d^{\pi_{\theta_k}}\) gives \[ \bar D_{\mathrm{KL}}(\theta_k\!\parallel\!\theta_k+\Delta\theta) = \mathbb{E}_{s\sim d^{\pi_{\theta_k}}}[f_s(\theta_k+\Delta\theta)] = \frac{1}{2}\,\Delta\theta^\top \underbrace{\mathbb{E}_{s\sim d^{\pi_{\theta_k}}}[F_s(\theta_k)]}_{F(\theta_k)} \,\Delta\theta \;+\; \mathcal{O}(\|\Delta\theta\|^3). \]
Conclusion. The Fisher information \(F(\theta_k)\) is exactly the Hessian of the expected KL at \(\theta_k\). Therefore, the KL trust-region constraint admits the quadratic local approximation \[ \bar D_{\mathrm{KL}}(\theta_k\!\parallel\!\theta_k+\Delta\theta)\;\approx\;\frac{1}{2}\,\Delta\theta^\top F(\theta_k)\,\Delta\theta, \] which yields the TRPO/NPG quadratic constraint and identifies \(F(\theta_k)\) as the local metric tensor of the policy manifold.
3.4.6 Trust Region Policy Optimization
The NPG algorithm presented above leverages a leading-order approximation of the KL-constrained policy optimization problem (3.51).
In Trust Region Policy Optimization (Schulman, Levine, et al. 2015), we still use the leading-order approximation to obtain the natural policy gradient direction, but additionally, we perform a backtracking line search to enforce the true (nonlinear) KL constraint and surrogate improvement.
The following pseudocode implements TRPO with GAE as the critic.
Inputs: initial policy \(\theta_0\); value/critic parameters \(\phi_0\); discount \(\gamma\); GAE parameter \(\lambda\); KL radius \(\delta\); CG iterations \(K_{\mathrm{cg}}\); backtrack factor \(\beta\in(0,1)\); max backtracks \(M\).
For iterations \(k=0,1,2,\dots\):
Collect rollouts (on-policy). Run \(\pi_{\theta_k}\) to obtain trajectories; build a batch \(\{(s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\}_{t=1}^N\).
Critic / advantages (GAE).
Compute TD residuals \(\delta_t = r_t + \gamma(1-\mathrm{done}_t)V_\phi(s_{t+1}) - V_\phi(s_t)\);
backward recursion \(\widehat{A}_t = \delta_t + \gamma\lambda(1-\mathrm{done}_t)\widehat{A}_{t+1}\), with \(\widehat{A}_{T}=0\);
(optionally) standardize \(\widehat{A}\) within the batch; set value targets \(\widehat{V}^{\,\text{targ}}_t=\widehat{A}_t+V_\phi(s_t)\).Value function update. Fit \(V_\phi\) by minimizing \(\sum_t (V_\phi(s_t)-\widehat{V}^{\,\text{targ}}_t)^2\) (one or several epochs).
Policy gradient at \(\theta_k\).
\[ g \;=\; \nabla_\theta L_{\theta_k}(\theta)\big|_{\theta=\theta_k} \approx \frac{1}{N} \sum_{t} \nabla_\theta \log \pi_{\theta_k}(a_t \mid s_t )\,\widehat{A}_t . \]Fisher–vector product (FvP). Define the Fisher information under \(\pi_{\theta_k}\): \[ F(\theta_k)\;=\;\mathbb{E}\Big[\nabla_\theta \log \pi_{\theta_k}(a\mid s)\,\nabla_\theta \log \pi_{\theta_k}(a\mid s)^\top\Big]. \] Implement \(v\mapsto Fv\) via the Hessian-vector product of the empirical KL.
Conjugate gradient (CG) solve. Approximately solve \(F p = g\) with \(K_{\mathrm{cg}}\) CG iterations to get the natural direction \(p_{\text{NPG}}\approx F^{-1}g\).
Compute step size for the quadratic trust region.
\[ \alpha \;\leftarrow\; \sqrt{\frac{2\delta}{p^\top_{\text{NPG}} F p_{\text{NPG}} }}. \] Candidate update: \(\theta^\star \leftarrow \theta_k + \alpha p_{\text{NPG}}\).Backtracking line search (feasibility + improvement). Repeatedly set \(\theta^\star \leftarrow \theta_k + \beta^j \alpha p_{\text{NPG}}\) for \(j=0,1,\dots,M\) until both hold on the batch:
- KL constraint: \(\bar D_{\mathrm{KL}}(\theta_k\,\|\,\theta^\star) \le \delta\).
- Surrogate improvement: \(L_{\theta_k}(\theta^\star) \ge L_{\theta_k}(\theta_k)\).
Accept the first \(\theta^\star\) that satisfies both; set \(\theta_{k+1}\leftarrow \theta^\star\).
3.4.6.1 Backtracking Line Search
Batch-only evaluation. During TRPO’s line search you do not collect new trajectories. All checks are computed on the same batch gathered with the old policy \(\pi_{\theta_k}\) (i.e., under \(d^{\pi_{\theta_k}}\)).
Given: a candidate update \(\theta^\star = \theta_k + \beta^j \alpha p_{\text{NPG}}\).
Empirical KL constraint (nonlinear, “true” KL). Compute the state-wise KL between the full action distributions of the old and candidate policies and average over the batch states: \[ \widehat{\bar D}_{\mathrm{KL}}(\theta_k \,\|\, \theta^\star) \;=\; \frac{1}{|\mathcal{B}|}\sum_{s\in\mathcal{B}} D_{\mathrm{KL}}\!\big(\pi_{\theta_k}(\cdot\mid s)\,\|\,\pi_{\theta^\star}(\cdot\mid s)\big). \]
- Categorical policy:
\[ D_{\mathrm{KL}}(\pi_{\theta_k}\,\|\,\pi_{\theta^\star}) \;=\; \sum_{a} \pi_{\theta_k}(a\mid s)\, \Big[\log \pi_{\theta_k}(a\mid s)-\log \pi_{\theta^\star}(a\mid s)\Big]. \] - Gaussian policy (mean \(\mu(s),\) covariance \(\Sigma(s)\); use pre-squash distribution if actions are squashed):
\[ D_{\mathrm{KL}}\big(\mathcal{N}(\mu_k,\Sigma_k)\,\|\,\mathcal{N}(\mu_\star,\Sigma_\star)\big) = \frac{1}{2}\Big( \operatorname{tr}(\Sigma_\star^{-1}\Sigma_k) + (\mu_\star-\mu_k)^\top \Sigma_\star^{-1}(\mu_\star-\mu_k) - d + \log\tfrac{\det \Sigma_\star}{\det \Sigma_k} \Big). \] Feasibility test: accept if \(\widehat{\bar D}_{\mathrm{KL}}(\theta_k \,\|\, \theta^\star) \le \delta\) (cf. (3.50)).
- Categorical policy:
Surrogate improvement. Evaluate the TRPO surrogate \(L_{\theta_k}(\theta)\) (cf. (3.49)) on the same batch using importance ratios from \(\theta^\star\): \[ \widehat{L}_{\theta_k}(\theta^\star) \;=\; \frac{1}{|\mathcal{B}|}\sum_{(s,a)\in\mathcal{B}} \frac{\pi_{\theta^\star}(a\mid s)}{\pi_{\theta_k}(a\mid s)}\, \widehat{A}^{\,\pi_{\theta_k}}(s,a), \qquad \widehat{L}_{\theta_k}(\theta_k)=\frac{1}{|\mathcal{B}|}\sum_{(s,a)}\widehat{A}^{\,\pi_{\theta_k}}(s,a). \] Improvement test: accept if \(\widehat{L}_{\theta_k}(\theta^\star)\ge \widehat{L}_{\theta_k}(\theta_k)\).
Backtracking loop (on-batch). Decrease the step by \(\beta\in(0,1)\) until both tests pass or a maximum of \(M\) backtracks is reached: \[ \theta^\star \leftarrow \theta_k + \beta^j \alpha p_{\text{NPG}},\quad j=0,1,\dots,M. \] If successful, set \(\theta_{k+1}\leftarrow \theta^\star\); otherwise keep \(\theta_{k+1}\leftarrow \theta_k\).
3.4.7 Proximal Policy Optimization
While NPG/TRPO are stable, they may be computationally heavier due to constrained solves or natural-step systems. Proximal Policy Optimization (PPO) (Schulman et al. 2017) replaces the hard constraint with a penalized (regularized) objective and optimizes it with standard first-order SGD: \[\begin{equation} \ell_k(\theta) \;=\; \mathbb{E}_{s \sim d^{\pi_{\theta_k}},a\sim \pi_{\theta_k}} \big[\,\rho_\theta(s,a)\, \widehat{A}^{\,\pi_{\theta_k}}(s,a)\,\big] \;-\; \lambda\; \mathbb{E}_{s \sim d^{\pi_{\theta_k}},a\sim \pi_{\theta_k}} \!\left[\log\frac{\pi_{\theta_k}(a\mid s)}{\pi_\theta(a\mid s)}\right], \tag{3.56} \end{equation}\] where \(\lambda > 0\) and the second term is the per-sample KL penalty that discourages large departures from \(\pi_{\theta_k}\). Conceptually, this is a Lagrangian relaxation of TRPO’s trust region, where the hard constraint is moved to the objective function as a soft penalty.
3.4.7.1 Gradient of the KL–Regularized Surrogate
Treat \(\widehat{A}^{\,\pi_{\theta_k}}\) and the sampling distribution as fixed during the policy update. Using \(\nabla_\theta \rho_\theta = \rho_\theta\,\nabla_\theta \log \pi_\theta\) and \(\nabla_\theta \log \frac{\pi_{\theta_k}}{\pi_\theta} = - \nabla_\theta \log \pi_\theta\), the gradient of the KL-regularized objective (3.56) is \[ \nabla_\theta \ell_k(\theta) \;=\; \mathbb{E}_{s \sim d^{\pi_{\theta_k}}, a\sim \pi_{\theta_k}} \!\Big[ \nabla_\theta \log \pi_\theta(a\mid s)\, \underbrace{\big(\rho_\theta(s,a)\,\widehat{A}(s,a)-\lambda\big)}_{\text{effective advantage}} \Big]. \qquad \tag{3.57} \] This shows the KL penalty shifts the effective advantage by \(-\lambda\).
3.4.7.2 From the Lagrangian Relaxation to PPO Updates
There are two standard PPO realizations:
PPO–KL (penalty version). Directly ascend \(\ell_k(\theta)\) with minibatch SGD: \[ \theta \leftarrow \theta + \alpha\; \frac{1}{B}\sum_{(s,a)\in\mathcal{B}} \nabla_\theta \log \pi_\theta(a\mid s)\, \big(\rho_\theta(s,a)\,\widehat{A}(s,a)-\lambda\big). \] After each epoch, measure the empirical KL \(\widehat{\bar D}_{\mathrm{KL}}(\theta_k\!\parallel\!\theta)\) on the batch; increase \(\lambda\) if KL is too high (tighten the region), decrease \(\lambda\) if it is too low.
PPO–Clip (clipping version). Replace the penalty with a hard trust region on the ratio \(\rho_\theta\). When \(\widehat{A}>0\), forbid \(\rho_\theta>1+\varepsilon\); when \(\widehat{A}<0\), forbid \(\rho_\theta<1-\varepsilon\). This yields the clipped objective \[\begin{equation} \hspace{-16mm} \ell^{\text{CLIP}}_k(\theta) \;=\; \mathbb{E}_{s \sim d^{\pi_{\theta_k}}, a \sim \pi_{\theta_k}} \Big[\min\!\big(\rho_\theta(s,a)\,\widehat{A}(s,a),\; \operatorname{clip}(\rho_\theta(s,a),\,1-\varepsilon,\,1+\varepsilon)\,\widehat{A}(s,a)\big)\Big], \tag{3.58} \end{equation}\] which is a first-order proxy to the Lagrangian/TRPO trust region: the min/clip term cancels the incentive to move \(\rho_\theta\) outside \([1-\varepsilon,1+\varepsilon]\) in directions that would further increase the objective.
Both versions are typically combined with a value-function loss and an entropy bonus to encourage exploration: \[ \mathcal{L}^{\text{PPO}}(\theta,\phi) = - \ell^{\text{PG}}_k(\theta) + c_v\,\mathbb{E}\big[(V_\phi(s)-\widehat{V}^{\,\text{targ}})^2\big] - c_e\,\mathbb{E}\big[\mathcal{H}(\pi_\theta(\cdot\mid s))\big], \] where \(\ell^{\text{PG}}_k\) is either \(\ell^{\text{CLIP}}_k\) or \(\ell_k\).
Why PPO “forbids” \(\rho_\theta\) from leaving \([1-\varepsilon,\,1+\varepsilon]\). Let \(r \equiv \rho_\theta(s,a)=\frac{\pi_\theta(a\mid s)}{\pi_{\theta_k}(a\mid s)}\) and \(\widehat{A}=\widehat{A}^{\,\pi_{\theta_k}}(s,a)\). The PPO–Clip objective for one sample is \[ L^{\text{CLIP}}(r,\widehat{A}) = \min\!\big(r\,\widehat{A},\ \operatorname{clip}(r,1-\varepsilon,1+\varepsilon)\,\widehat{A}\big). \]
Let’s do a case analysis, as shown in Fig. 3.16.
If \(\widehat{A}>0\): increasing \(r\) (i.e., increasing \(\pi_\theta(a\mid s)\)) raises the unclipped term \(r\,\widehat{A}\).
The clipped term equals \((1+\varepsilon)\widehat{A}\) whenever \(r>1+\varepsilon\). Hence \[ L^{\text{CLIP}}(r,\widehat{A}) = \begin{cases} r\,\widehat{A}, & r\le 1+\varepsilon,\\[4pt] (1+\varepsilon)\widehat{A}, & r>1+\varepsilon, \end{cases} \] so \(\frac{\partial L^{\text{CLIP}}}{\partial r}=\widehat{A}\) for \(r\le 1+\varepsilon\) and \(0\) for \(r>1+\varepsilon\). There is no further gain by pushing \(r\) beyond \(1+\varepsilon\); the gradient vanishes.
Intuitively: don’t increase an action’s probability too much even if it looks good—stay proximal.If \(\widehat{A}<0\): decreasing \(r\) (i.e., reducing \(\pi_\theta(a\mid s)\)) lowers the unclipped term \(r\,\widehat{A}\). The clipped term equals \((1-\varepsilon)\widehat{A}\) whenever \(r<1-\varepsilon\). Thus \[ L^{\text{CLIP}}(r,\widehat{A}) = \begin{cases} r\,\widehat{A}, & r\ge 1-\varepsilon,\\[4pt] (1-\varepsilon)\widehat{A}, & r<1-\varepsilon, \end{cases} \] so \(\frac{\partial L^{\text{CLIP}}}{\partial r}=\widehat{A}(<0)\) for \(r\ge 1-\varepsilon\) and \(0\) for \(r<1-\varepsilon\). There is no incentive to shrink \(r\) below \(1-\varepsilon\); the gradient goes to zero.
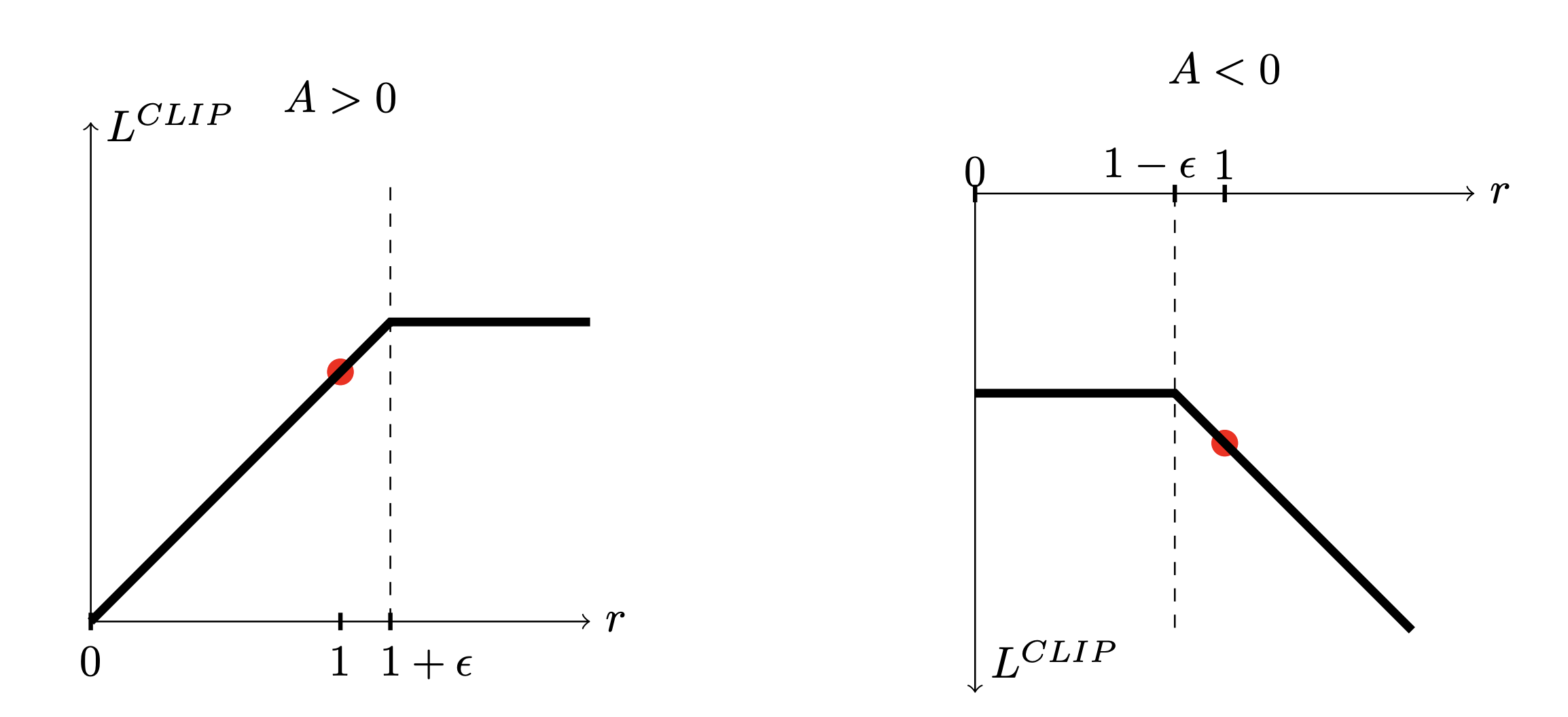
Figure 3.16: The clipped objective function in PPO (from the original PPO paper).
Therefore, the \(\min\) with a clipped ratio creates flat regions where the objective stops improving in the “profitable” outward direction. This removes the optimization incentive to move \(r\) outside \([1-\varepsilon,1+\varepsilon]\), implementing a per-sample trust region on the probability ratio while retaining the standard policy-gradient inside the bracket.
The following pseudocode implements PPO (clipped version) with GAE.
Inputs: policy \(\pi_\theta\), value \(V_\phi\), discount \(\gamma\), GAE \(\lambda\), clip \(\varepsilon\), coefficients \(c_v,c_e\), learning rate \(\alpha\), epochs \(K_{\text{epoch}}\), minibatch size \(B\).
For iterations \(k=0,1,2,\dots\):
Collect on-policy data. Roll out \(\pi_{\theta_k}\) to get trajectories \(\{(s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\}\).
Cache \(\log \pi_{\theta_k}(a_t\mid s_t)\).Compute GAE advantages and value targets.
\(\delta_t = r_t + \gamma(1-\mathrm{done}_t) V_\phi(s_{t+1}) - V_\phi(s_t)\)
\(\widehat{A}_t = \delta_t + \gamma\lambda(1-\mathrm{done}_t)\widehat{A}_{t+1}\), with \(\widehat{A}_T=0\).
\(\widehat{V}^{\,\text{targ}}_t = \widehat{A}_t + V_\phi(s_t)\).
(Optionally standardize \(\{\widehat{A}_t\}\) within the batch.)Policy/Value optimization (multiple epochs).
For \(e=1,\dots,K_{\text{epoch}}\):- Split the batch into minibatches \(\mathcal{B}\) of size \(B\).
- For each \(\mathcal{B}\): \[ \rho_\theta(s,a) = \exp\!\big(\log\pi_\theta(a\mid s)-\log\pi_{\theta_k}(a\mid s)\big), \] \[ \ell^{\text{CLIP}}_{\mathcal{B}}(\theta) = \frac{1}{B}\sum_{(s,a)\in\mathcal{B}} \min\!\big(\rho_\theta\,\widehat{A},\; \operatorname{clip}(\rho_\theta,1-\varepsilon,1+\varepsilon)\,\widehat{A}\big), \] \[ \ell^{\text{VAL}}_{\mathcal{B}}(\phi)= \frac{1}{B}\sum_{s\in\mathcal{B}}(V_\phi(s)-\widehat{V}^{\,\text{targ}})^2,\quad \mathcal{H}_{\mathcal{B}}(\theta)=\frac{1}{B}\sum_{s\in\mathcal{B}}\mathcal{H}(\pi_\theta(\cdot\mid s)). \]
- The total loss to be minimized is \[ \mathcal{J}_{\mathcal{B}}(\theta,\phi) = - \ell^{\text{CLIP}}_{\mathcal{B}}(\theta) + c_v\,\ell^{\text{VAL}}_{\mathcal{B}}(\phi) - c_e\,\mathcal{H}_{\mathcal{B}}(\theta). \]
- Take an optimizer step on \(\mathcal{J}_{\mathcal{B}}\) (e.g., Adam with learning rate \(\alpha\)).
- Split the batch into minibatches \(\mathcal{B}\) of size \(B\).
(Optional) Early stopping by KL.
Estimate \(\widehat{\bar D}_{\mathrm{KL}}(\theta_k\!\parallel\!\theta)\) on the whole batch; stop inner epochs early if it exceeds a threshold.
3.4.8 Soft Actor–Critic
Standard actor–critic methods maximize expected return. Soft Actor–Critic (SAC) augments the objective with an entropy bonus that explicitly encourages exploration and robustness while remaining off-policy and sample efficient (Haarnoja et al. 2018). We first introduce a minimal implementation of SAC for discrete actions, then present full SAC with additional techniques for continuous actions.
3.4.8.1 SAC for Discrete Actions
Entropy of A Probability Distribution. Given a probability distribution \(P\) supported on the set \(\mathcal{X}\), the entropy of the distribution is defined as \[\begin{equation} \mathcal{H}(P) = - \sum_{x \in \mathcal{X}} P(x) \log P(x) = - \mathbb{E}_{x \sim P} \log P(x). \tag{3.59} \end{equation}\] Since \(0 \leq P(x) \leq 1\) for any \(x\), it is clear that \(\mathcal{H}(P) \geq 0\) for any distribution \(P\).
Suppose the set \(\mathcal{X}\) has \(N\) elements \(x_1,\dots,x_N\), and suppose \(P(x_i) = p_i \geq 0,i=1,\dots,N\). We claim that the distribution \(P^\star\) that maximizes \(\mathcal{H}(P)\) is such that \(p^\star_i = \frac{1}{N},i=1,\dots,N\).
To show this, consider the function \(\log t\) that is concave for \(t > 0\). Using Jensen’s inequality, we have that \[\begin{equation} \begin{split} \mathcal{H}(P) & = - \sum_{x} P(x) \log P(x) = \sum_{x} P(x) \log \frac{1}{P(x)} \\ & \leq \log \left( \sum_{x} P(x) \frac{1}{P(x)} \right) \\ & = \log N, \end{split} \end{equation}\] with the equality holds if and only if \(P(x_1)=P(x_2)=\dots=P(x_N) = \frac{1}{N}\). Therefore, maximizing the entropy \(\mathcal{H}(P)\) encourages the distribution \(P\) to have a density function that spreads out evenly over the set \(\mathcal{X}\).
Maximum-Entropy Objective. SAC maximizes the soft objective \[\begin{equation} \begin{split} J(\pi) &= \mathbb{E}\!\left[\sum_{t}\gamma^t\Big(R(s_t,a_t)\;+\;\alpha\,\mathcal{H}\!\left(\pi(\cdot\mid s_t)\right)\Big)\right], \\ \mathcal{H}(\pi(\cdot\mid s)) &= -\mathbb{E}_{a\sim\pi}[\log \pi(a\mid s)], \end{split} \tag{3.60} \end{equation}\] where the entropy function \(\mathcal{H}(\cdot)\) encourages the policy to explore, and the temperature \(\alpha>0\) balances reward maximization against exploration.
Given a trajectory \(\tau = (s_0, a_0, r_0, s_1, a_1,\dots)\), define the soft return: \[ g_t = \sum_{t=0} \gamma^t \left( R(s_t, a_t) - \alpha \log \pi (a_t \mid s_t) \right). \] This leads to the “soft” state value and soft action value associated with \(\pi\): \[\begin{equation} \begin{split} V^\pi(s) & = \mathbb{E}_{a\sim\pi}\left[Q^\pi(s,a)\;-\;\alpha\log\pi(a\mid s)\right], \\ Q^\pi(s,a) & = R(s,a) + \gamma\,\mathbb{E}_{s'} \left[V^\pi(s')\right]. \end{split} \tag{3.61} \end{equation}\] Combining the two equations above, we obtain a soft Bellman Consistency equation on the \(Q\) value: \[\begin{equation} Q^{\pi}(s,a) = R(s, a) + \gamma \mathbb{E}_{s'} \left[ \mathbb{E}_{a' \sim \pi} \left[ Q^\pi(s', a') - \alpha \log \pi(a' \mid s') \right] \right]. \tag{3.62} \end{equation}\]
Critic Update. For a replay sample \((s,a,r,s')\), assuming discrete actions, we can compute the target \(Q\) value following the soft Bellman Consistency equation (3.62) \[\begin{equation} y \;=\; r + \gamma \sum_{a'} \pi_{\theta} (a' \mid s') \left( Q_{\bar{\psi}}(s', a') - \alpha \log \pi_\theta (a' \mid s') \right) \tag{3.63} \end{equation}\] where \(Q_{\bar{\psi}}\) is the target Q network inspired by DQN to mitigate the deadly triad. The critic loss is therefore \[\begin{equation} \mathcal{L}_Q(\psi) \;=\; \mathbb{E}_{(s,a) \sim \mathcal{D}}\big[\big(Q_{\psi}(s,a)-y\big)^2\big], \tag{3.64} \end{equation}\] where the expectation is taken over a minibatch drawn from the replay buffer.
Actor Update. Given the learned critic \(Q_\psi\) and replay state distribution \(s \sim \mathcal{D}\), the SAC policy improvement step chooses \(\pi_\theta\) to minimize, for each state, the soft advantage–regularized objective \[\begin{equation} J_\pi(\theta) \;=\; \mathbb{E}_{s\sim\mathcal{D}} \left[ \sum_{a} \pi_\theta(a\mid s)\left( \alpha\,\log \pi_\theta(a\mid s) - Q_\psi(s,a)\right) \right]. \tag{3.65} \end{equation}\] For discrete actions, the expectation over \(a\) is a finite sum—no action sampling is required.
Differentiating (3.65) yields the policy gradient \[\begin{equation} \nabla_\theta J_\pi(\theta) = \mathbb{E}_{s\sim\mathcal{D}} \left[ \sum_{a} \nabla_\theta \pi_\theta(a\mid s)\; \Big(\alpha\,[1+\log \pi_\theta(a\mid s)] - Q_\psi(s,a)\Big) \right]. \tag{3.66} \end{equation}\]
The following pseudocode implements a basic SAC algorithm with discrete actions.
Inputs: replay buffer \(\mathcal{D}\); policy \(\pi_\theta(a\mid s)\) over \(K\) actions; single critic \(Q_{\psi}(s,\cdot)\) (returns a \(K\)-vector); target critic parameters \(\bar\psi\); discount \(\gamma\); temperature \(\alpha\) (learned or fixed); Polyak \(\tau\in(0,1]\); batch size \(B\); stepsizes \(\alpha_\theta,\alpha_\psi\).
Initialize: \(\bar\psi \leftarrow \psi\).
For iterations \(k=0,1,2,\dots\):
Interaction.
Observe \(s_t\). Sample \(a_t \sim \pi_\theta(\cdot\mid s_t)\); step env to get \((s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\); push to \(\mathcal{D}\).Sample minibatch.
Draw \(B\) transitions \(\{(s,a,r,s',d)\}\) from \(\mathcal{D}\).Target computation (single target network).
- Compute \(\pi_\theta(\cdot\mid s')\) and \(\log \pi_\theta(\cdot\mid s')\).
- Evaluate target critic \(Q_{\bar\psi}(s',\cdot)\).
- Soft value target:
\[ V_{\text{tgt}}(s')=\Big\langle \pi_\theta(\cdot\mid s'),\; Q_{\bar\psi}(s',\cdot)-\alpha\,\log \pi_\theta(\cdot\mid s') \Big\rangle. \] - Bellman target:
\[ y \leftarrow r + \gamma(1-d)\,V_{\text{tgt}}(s'). \] (Matches (3.63) with one target network.)
Critic update. Minimize the squared error (cf. (3.64)):
\[ \psi \leftarrow \psi - \alpha_\psi \nabla_{\psi}\;\frac{1}{B}\sum\nolimits_{(s,a,r,s',d)} \big(Q_{\psi}(s,a)-y\big)^2. \]Actor update. Minimize (cf. (3.65)):
\[ \theta \leftarrow \theta - \alpha_\theta \nabla_\theta \frac{1}{B}\sum_s \sum_{a} \pi_\theta(a\mid s)\,\Big(\alpha\,\log \pi_\theta(a\mid s)-Q_{\psi}(s,a)\Big). \]Target critic (Polyak).
\[ \bar\psi \;\leftarrow\; \tau\,\psi \;+\; (1-\tau)\,\bar\psi. \]
The next example applies the SAC algorithm above to the cart-pole problem.
Example 3.7 (SAC for Cart-pole Balancing) We use a fixed temperature \(\alpha=0.2\).
Fig. 3.17 shows the learning curve of SAC.
Fig. 3.18 shows a sample rollout of the learned policy.
You can find the code here. Play with the temperature parameter.

Figure 3.17: Learning curve (Soft Actor–Critic).
Figure 3.18: Policy rollout (Soft Actor–Critic).
3.4.8.2 SAC for Continuous Actions
In continuous action spaces we cannot sum over actions. SAC therefore:
samples actions from the current policy using a reparameterization trick (low-variance gradients), and
computes the soft Bellman target with those sampled actions and a twin-target minimum to reduce overestimation.
Reparameterization (pathwise) Gradient. Let the stochastic policy be a Gaussian in unconstrained space, squashed by tanh to the action bounds:
\[
u \;=\; \mu_\theta(s)\;+\;\sigma_\theta(s)\odot\varepsilon,\quad \varepsilon\sim\mathcal N(0,I),
\qquad
a \;=\; \tanh(u)\cdot a_{\text{scale}} + a_{\text{bias}},
\]
where \(\sigma_\theta(s)\) outputs per-dimension standard deviation.
This gives a differentiable map \(a=f_\theta(s,\varepsilon)\). Expectations over \(a\sim \pi_\theta(\cdot\mid s)\) are then written as expectations over \(\varepsilon\), so gradients can flow through \(f_\theta\) (the pathwise derivative). The correct log-density under the squashed policy uses change-of-variables:
\[
\log\pi_\theta(a\mid s)
\;=\;
\log\mathcal N\!\big(u;\mu_\theta(s),\sigma_\theta^2(s)\big)
\;-\;\sum_i \log\!\big(1-\tanh^2(u_i)\big)
\;+\;\text{constant}.
\]
The intuition here is that the tanh function is a nonlinear transformation that distorts the original Gaussian distribution. This “tanh correction” is crucial for stable training.
Critic Update. Maintain two critics \(Q_{\psi_1},Q_{\psi_2}\) and their target copies \(Q_{\bar\psi_1},Q_{\bar\psi_2}\). For a replay minibatch \((s,a,r,s',d)\), form the target by drawing a next action from the current policy: \[\begin{equation} a' \sim \pi_\theta(\cdot\mid s'),\qquad y \;=\; r \;+\; \gamma(1-d)\,\Big( \min\nolimits_{j=1,2} Q_{\bar\psi_j}(s',a') \;-\; \alpha \log\pi_\theta(a'\mid s') \Big). \tag{3.67} \end{equation}\] Each critic minimizes the squared error to \(y\) (with stop-grad on \(y\)): \[ \mathcal L_Q(\psi_j) \;=\; \mathbb{E}\big[(Q_{\psi_j}(s,a)-y)^2\big],\quad j=1,2, \] where the expectation is taken over the distribution in the replay buffer.
Actor Update. The actor minimizes the soft objective under the replay state distribution: \[\begin{equation} J_\pi(\theta) \;=\; \mathbb{E}_{s\sim\mathcal D,\,\varepsilon}\left[ \alpha\,\log\pi_\theta \big(f_\theta(s,\varepsilon)\mid s\big) -\min\nolimits_{j=1,2} Q_{\psi_j} \big(s,f_\theta(s,\varepsilon)\big) \right]. \tag{3.68} \end{equation}\] By reparameterization, the gradient flows through both the explicit \(\log\pi_\theta\) term and the path \(a=f_\theta(s,\varepsilon)\). Particularly, denote \(Q_\psi(\cdot, \cdot) = \min_{j=1,2} Q_{\psi_j} (\cdot, \cdot)\), we have that \[ \nabla_\theta J_\pi(\theta) = \mathbb{E}_{s,\varepsilon} \left[ \alpha \nabla_\theta \log \pi_\theta (a \mid s) + \left( \alpha \nabla_a \log \pi_\theta(a \mid s) - \nabla_a Q_\psi (s,a) \right) \nabla_\theta f_\theta (s, \varepsilon) \right]_{a=f_\theta(s,\varepsilon)}. \] In code, you typically just write the loss \[ \mathbb{E}_{s, \varepsilon}\left[ \alpha \log \pi_\theta (a \mid s) - Q_\psi (s, a) \right], \quad a = f_\theta(s, \varepsilon), \] and autodiff will automatically compute the correct gradient.
Tuning \(\alpha\) (Temperature). \(\alpha\) trades off reward pursuit vs. policy entropy. A fixed \(\alpha\) is problem-dependent. SAC treats \(\alpha\) as a dual variable to enforce a target entropy \(\bar{\mathcal H}\) (often \(-\text{dim}(\mathcal A)\)): \[ J(\alpha)\;=\;\mathbb{E}_{s\sim\mathcal D,\,a\sim\pi_\theta}\!\Big[-\alpha\big(\log \pi_\theta(a\mid s)+\bar{\mathcal H}\big)\Big], \quad \log\alpha \leftarrow \log\alpha - \alpha_\alpha \nabla_{\log\alpha} J(\alpha). \] This adapts exploration automatically across tasks and training phases.
Inputs: replay buffer \(\mathcal{D}\); policy \(\pi_\theta(a\mid s)\) reparameterized by \(a=f_\theta(s,\varepsilon)\) with tanh-squashed Gaussian; twin critics \(Q_{\psi_1},Q_{\psi_2}\); twin target critics with params \(\bar\psi_1,\bar\psi_2\); discount \(\gamma\); temperature \(\alpha\) (learned or fixed); Polyak \(\tau\in(0,1]\); batch size \(B\); stepsizes \(\alpha_\theta,\alpha_\psi,\alpha_\alpha\).
Initialize: \(\bar\psi_j \leftarrow \psi_j\) for \(j\in\{1,2\}\).
For iterations \(k=0,1,2,\dots\):
Interaction.
Observe \(s_t\). Sample \(\varepsilon_t\sim\mathcal N(0,I)\), set \(a_t=f_\theta(s_t,\varepsilon_t)\); step env to get \((s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\); push to \(\mathcal{D}\).Sample minibatch.
Draw \(B\) transitions \(\{(s,a,r,s',d)\}\) from \(\mathcal{D}\).Target computation (twin targets, reparameterized next action).
- Sample \(\varepsilon'\sim\mathcal N(0,I)\), set \(a'=f_\theta(s',\varepsilon')\).
- Compute \(\log\pi_\theta(a'\mid s')\) with tanh correction.
- Evaluate target critics \(Q_{\bar\psi_1}(s',a')\), \(Q_{\bar\psi_2}(s',a')\); let \(Q_{\min}(s',a')=\min\{Q_{\bar\psi_1},Q_{\bar\psi_2}\}\).
- Bellman target:
\[ y \leftarrow r + \gamma(1-d)\,\big(Q_{\min}(s',a') - \alpha\,\log\pi_\theta(a'\mid s')\big). \] (Stop gradient through \(y\).)
Critic updates (both heads).
\[ \psi_j \leftarrow \psi_j - \alpha_\psi \nabla_{\psi_j}\;\frac{1}{B}\sum (Q_{\psi_j}(s,a)-y)^2,\quad j=1,2. \]Actor update (reparameterized).
- For each \(s\) in the batch, sample \(\varepsilon\), set \(a=f_\theta(s,\varepsilon)\).
- Actor objective:
\[ J_\pi(\theta)=\frac{1}{B}\sum_s \Big(\alpha\,\log\pi_\theta(a\mid s)-\min\nolimits_j Q_{\psi_j}(s,a)\Big). \] - Update: \[ \theta \leftarrow \theta - \alpha_\theta \nabla_\theta J_\pi(\theta). \]
Temperature (optional).
With target entropy \(\bar{\mathcal H}\) and parameter \(\log\alpha\): \[ J(\alpha)=\frac{1}{B}\sum_s \big[-\alpha(\log\pi_\theta(a\mid s)+\bar{\mathcal H})\big],\quad \log\alpha \leftarrow \log\alpha - \alpha_\alpha \nabla_{\log\alpha} J(\alpha),\quad \alpha\leftarrow e^{\log\alpha}. \]Target critics (Polyak). For \(j=1,2\): \[ \bar\psi_j \;\leftarrow\; \tau\,\psi_j \;+\; (1-\tau)\,\bar\psi_j. \]
The next example applies SAC to Inverted Pendulum.



3.4.9 Deterministic Policy Gradient
In continuous-control tasks, sampling or integrating over actions inside policy gradients is costly and noisy. The Deterministic Policy Gradient (DPG) framework (Silver et al. 2014) replaces the stochastic policy \(\pi_\theta(a\mid s)\) with a deterministic actor \[ a = \mu_\theta(s)\in\mathbb{R}^m. \] Its state–action value and discounted state visitation measure are \[ Q^{\mu_\theta}(s,a) \;=\; \mathbb{E}\!\left[\sum_{t=0}^\infty \gamma^t R(s_t,a_t)\,\middle|\,s_0=s,\ a_0=a,\ a_{t>0}=\mu_\theta(s_t)\right], \] \[ \rho^{\pi}(s) \;=\; \sum_{t=0}^{\infty}\gamma^t \Pr(s_t=s \mid a_t\sim \pi(\cdot\mid s_t)),\qquad \rho^{\mu_\theta}\equiv \rho^{\pi=\mu_\theta}. \]
We consider two objectives:
On-policy objective: \[\begin{equation} J(\theta)\;=\;\mathbb{E}_{s\sim \rho^{\mu_\theta}}\big[\,Q^{\mu_\theta}(s,\mu_\theta(s))\,\big]. \tag{3.69} \end{equation}\]
Off-policy surrogate (with behavior policy \(\beta\)): \[\begin{equation} J_\beta(\theta)\;=\;\mathbb{E}_{s\sim \rho^{\beta}} \big[\,Q^{\mu_\theta}(s,\mu_\theta(s))\,\big]. \tag{3.70} \end{equation}\]
The on-policy objective (3.69) is the usual RL objective in policy gradient methods, as \(Q^{\mu_\theta}(s, \mu_\theta(s)) = V^{\mu_\theta}(s)\) by definition.
A key result in Deterministic Policy Gradient is that under mild conditions, optimizating the surrogate off-policy objective (3.70) is the same as optimizating the original on-policy objective.
To see this, assume
- \(R\) and \(P(\cdot\mid s,a)\) (the transition dynamics) are bounded/measurable; \(Q^{\mu_\theta}\) exists and is continuously differentiable in \(a\);
- \(\mu_\theta(s)\) is continuously differentiable in \(\theta\);
- Interchange of integration and differentiation is valid (e.g., dominated convergence).
Then, the on-policy and off-policy deterministic policy gradients (DPG) are:
On-policy DPG. \[\begin{equation} \nabla_\theta J(\theta) \;=\; \mathbb{E}_{s\sim \rho^{\mu_\theta}} \left[ \nabla_\theta \mu_\theta(s)\; \nabla_a Q^{\mu_\theta}(s,a)\big|_{a=\mu_\theta(s)} \right]. \tag{3.71} \end{equation}\]
Off-policy DPG. For any behavior policy \(\beta\) with visitation \(\rho^\beta\), \[\begin{equation} \nabla_\theta J_\beta(\theta) \;=\; \mathbb{E}_{s\sim \rho^{\beta}} \left[ \nabla_\theta \mu_\theta(s)\; \nabla_a Q^{\mu_\theta}(s,a)\big|_{a=\mu_\theta(s)} \right]. \tag{3.72} \end{equation}\]
In particular, the off-policy DPG (3.72) can be estimated from replay sampled under \(\beta\) without action-importance ratios; only the state weighting changes.
The following result states that the on-policy and off-policy objectives share the same stationary points.
Theorem 3.9 (Common First-Order Optima) Let \[\begin{equation} g(s;\theta)\;:=\;\nabla_\theta \mu_\theta(s)\,\nabla_a Q^{\mu_\theta}(s,a)\big|_{a=\mu_\theta(s)}\in\mathbb{R}^{d}, \tag{3.73} \end{equation}\] where \(d\) is the dimension of \(\theta\).
Suppose \(\rho^\beta\) has coverage of the on-policy support, i.e., \[ \text{supp}(\rho^{\mu_\theta})\ \subseteq\ \text{supp}(\rho^\beta),\quad \text{and}\quad \rho^\beta(s)>0\ \text{a.e. on }\text{supp}(\rho^{\mu_\theta}). \] If \(g(s;\theta^\star)=0\) for \(\rho^{\mu_{\theta^\star}}\)-almost every \(s\) (in particular, if \(\mu_{\theta^\star}\) is greedy w.r.t. \(Q^{\mu_{\theta^\star}}\), so \(\nabla_a Q^{\mu_{\theta^\star}}(s,a)|_{a=\mu_{\theta^\star}(s)}=0\) for all \(s\)), then \[ \nabla_\theta J(\theta^\star)=0 \quad\text{and}\quad \nabla_\theta J_\beta(\theta^\star)=0. \] Thus any deterministic policy satisfying the first-order optimality condition (greedy w.r.t. its own \(Q\)) is a stationary point of both \(J\) and \(J_\beta\), regardless of the (covered) state weighting.
If additionally \(\text{supp}(\rho^{\mu_\theta})=\text{supp}(\rho^\beta)\) and both are strictly positive on that support, then \[ \nabla_\theta J(\theta)=0 \ \Longleftrightarrow\ \nabla_\theta J_\beta(\theta)=0. \]
Remarks.
The off-policy objective \(J_\beta\) changes only the weights over states; the per-state improvement direction \(g(s;\theta)\) is identical. With sufficient coverage, ascent on \(J_\beta\) improves \(J\) and shares its stationary points.
In practice, DDPG uses exploration noise to expand support of \(\rho^\beta\) and target networks to stabilize \(Q^{\mu_\theta}\), making the off-policy gradient estimate reliable.
From DPG to DDPG (Deep DPG). DDPG (Lillicrap et al. 2015) implements DPG with deep networks + standard stabilizers:
- Replay buffer \(\mathcal D\) for off-policy sample efficiency.
- Target networks \(\mu_{\bar\theta}, Q_{\bar\psi}\) with Polyak averaging to stabilize TD targets.
- Exploration noise added to the deterministic action: \(a_t = \mu_\theta(s_t) + \varepsilon_t\) (original paper used Ornstein–Uhlenbeck noise; Gaussian works well too).
High-Level Algorithm (DDPG).
Interact off-policy. Act with exploration: \(a_t=\mu_\theta(s_t)+\varepsilon_t\). Store \((s_t,a_t,r_t,s_{t+1},\text{done}_t)\) in \(\mathcal D\).
Critic TD(0). For a minibatch from \(\mathcal D\), \[ y = r + \gamma(1-\text{done})\,Q_{\bar\psi} \big(s',\,\mu_{\bar\theta}(s')\big),\qquad \min_\psi\ \frac{1}{B}\sum (Q_\psi(s,a)-y)^2. \]
Actor DPG step. \[ \max_\theta\ \frac{1}{B}\sum Q_\psi\big(s,\,\mu_\theta(s)\big) \quad\Longleftrightarrow\quad \nabla_\theta J \approx \frac{1}{B}\sum \nabla_\theta \mu_\theta(s)\,\nabla_a Q_\psi(s,a)\big|_{a=\mu_\theta(s)}. \]
Targets Polyak update. \[ \bar\theta \leftarrow \tau\,\theta + (1-\tau)\bar\theta,\ \ \bar\psi \leftarrow \tau\,\psi + (1-\tau)\bar\psi. \]
Remarks.
- No entropy bonus or log-probabilities (in contrast to SAC). Exploration comes from additive noise.
- Overestimation and sensitivity to hyperparameters can appear; target networks, small actor steps, and proper normalization help.
The following pseudocode implements DDPG.
Inputs: replay buffer \(\mathcal{D}\); deterministic actor \(\mu_\theta(s)\); critic \(Q_\psi(s,a)\); target networks \(\mu_{\bar\theta}, Q_{\bar\psi}\); discount \(\gamma\in[0,1)\); Polyak \(\tau\in(0,1]\); batch size \(B\); stepsizes \(\alpha_\theta,\alpha_\psi\); exploration noise process \(\varepsilon_t\sim \mathcal N(0,\sigma^2 I)\) (or Ornstein–Uhlenbeck).
Initialize: \(\bar\theta\leftarrow\theta,\ \bar\psi\leftarrow\psi\). Fill \(\mathcal D\) with a short random warm-up.
For iterations \(k=0,1,2,\dots\):
Interaction (off-policy).
Observe \(s_t\). Compute action with noise
\[ a_t \leftarrow \text{clip}\big(\mu_\theta(s_t) + \varepsilon_t,\ a_{\min}, a_{\max}\big). \] Step env to get \((s_t,a_t,r_t,s_{t+1},\mathrm{done}_t)\). Push into \(\mathcal D\).Sample minibatch.
Draw \(B\) transitions \(\{(s,a,r,s',d)\}\) from \(\mathcal D\).Critic target.
\[ a' \leftarrow \mu_{\bar\theta}(s'),\qquad y \leftarrow r + \gamma(1-d)\,Q_{\bar\psi}(s',a'). \] (Stop gradient through \(y\).)Critic update.
\[ \psi \leftarrow \psi - \alpha_\psi\,\nabla_\psi\ \frac{1}{B}\sum (Q_\psi(s,a)-y)^2. \]Actor update (DPG).
\[ \theta \leftarrow \theta + \alpha_\theta\ \frac{1}{B}\sum \Big[\ \nabla_\theta \mu_\theta(s)\ \nabla_a Q_\psi(s,a)\big|_{a=\mu_\theta(s)}\ \Big]. \] (Equivalently, ascend \(\frac{1}{B}\sum Q_\psi(s,\mu_\theta(s))\) by backprop.)Target networks (Polyak).
\[ \bar\theta \leftarrow \tau\,\theta + (1-\tau)\,\bar\theta,\qquad \bar\psi \leftarrow \tau\,\psi + (1-\tau)\,\bar\psi. \]
The next example applies DDPG to Inverted Pendulum.




3.5 Model-based Policy Optimization
Model-based policy optimization (MBPO) (Janner et al. 2019) sits between pure model-free methods (high variance, data hungry) and “plan-only” model-based control (sensitive to model bias, to be introduced in Chapter 4). The key idea is to learn a dynamics model and then use only short rollouts from that model to create extra training data for a strong off-policy learner (usually SAC).
Consider an MDP with unknown dynamics \(s_{t+1} \sim P( \cdot \mid s_t,a_t)\). MBPO learns an ensemble \(\{\hat f_{\psi_k}\}_{k=1}^K\) that predicts the next state (often the delta-state \(\Delta s\)). Rather than planning far ahead inside the learned model, MBPO:
Collects real transitions \(\mathcal{D}_{\text{env}}\) by interacting with the environment.
Fits the dynamics ensemble on \(\mathcal{D}_{\text{env}}\).
Periodically generates short rollouts (e.g., horizon \(H=1\ldots5\)) starting from real states by simulating with a random member of the ensemble, producing model transitions \(\mathcal{D}_{\text{model}}\).
Trains an off-policy actor-critic (e.g., SAC) on a mixture of \(\mathcal{D}_{\text{env}}\) and \(\mathcal{D}_{\text{model}}\), typically with a high fraction of model data but short \(H\) to limit bias.
This yields the sample-efficiency benefits of model-based learning while maintaining the robustness of model-free policy optimization.
The following pseudocode implements MBPO with SAC as the off-policy learner.
Model-based Policy Optimization (SAC as Off-Policy Learner)
Inputs: environment \(\mathcal{E}\), policy \(\pi_\theta(a\mid s)\), twin critics \(Q_{\phi_1},Q_{\phi_2}\) with targets, temperature \(\alpha\) (auto-tuned), dynamics ensemble \(\{\hat f_{\psi_k}\}_{k=1}^K\), real buffer \(\mathcal{D}_{\text{env}}\), model buffer \(\mathcal{D}_{\text{model}}\). Rollout horizon \(H\), model ratio \(p_{\text{model}}\in[0,1]\), update counts \(G_{\text{dyn}}, G_{\text{rl}}\).
- Warm-up & data collection.
- Interact with \(\mathcal{E}\) using \(\pi_\theta\) (or random for a short warm-up).
- Store \((s,a,r,s')\) in \(\mathcal{D}_{\text{env}}\).
- Fit dynamics. For \(G_{\text{dyn}}\) steps:
- Sample minibatch \(B\subset\mathcal{D}_{\text{env}}\).
- Update each \(\psi_k\) to predict \(\Delta s = s'-s\) (and optionally \(r\)) by minimizing, e.g, mean squared error.
- Short model rollouts (data generation).
- Sample seed states \(S_0\) from recent \(\mathcal{D}_{\text{env}}\).
- For each \(s\in S_0\)
- for \(h=1\ldots H\):
- Sample \(a\sim \pi_\theta(\cdot\mid s)\).
- Pick random ensemble member \(k\); predict \(\hat\Delta s \leftarrow \hat f_{\psi_k}(s,a)\); set \(\hat s' = s + \hat\Delta s\).
- Compute \(r\) via a learned reward model or a known formula (when available).
- Push \((s,a,r,\hat s',\texttt{done}=0)\) into \(\mathcal{D}_{\text{model}}\).
- Set \(s\leftarrow\hat s'\); break if time-limit reached.
- for \(h=1\ldots H\):
- Off-policy RL updates (SAC). For \(G_{\text{rl}}\) steps:
- Form a minibatch by drawing a fraction \(p_{\text{model}}\) from \(\mathcal{D}_{\text{model}}\) and \(1-p_{\text{model}}\) from \(\mathcal{D}_{\text{env}}\).
- Critic targets: \[ y=r+\gamma(1-d)\big[\min_j Q_{\phi_j^-}(s',a')-\alpha\log\pi_\theta(a'\mid s')\big], \] where \(a'\sim\pi_\theta(\cdot\mid s')\).
- Critic update: regress \(Q_{\phi_j}\) to \(y\) (both heads).
- Actor update: minimize \(J_\pi = \mathbb{E}_s\!\big[\alpha\log\pi_\theta(a\mid s) - \min_j Q_{\phi_j}(s,a)\big]\), with \(a\sim\pi_\theta\).
- Temperature update (optional): adjust \(\alpha\) towards target entropy.
- Soft-update target critics.
- Repeat steps 1–4 until convergence or iteration limits.
Notes.
Ensembles capture epistemic uncertainty; random-member rollouts implicitly regularize toward pessimism.
Keeping \(H\) short (e.g., \(1\!\!-\!\!5\)) is crucial to prevent model error explosion.
Use recent real states as rollout seeds to stay on-distribution.
The next example applies MBPO to Inverted Pendulum.



